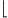 w(n+1)
w(n+1) 2
2 can exactly simulate general SOBPs of length n and width w, and moreover an n2−o(n) blow-up in width is necessary for such a simulation.
can exactly simulate general SOBPs of length n and width w, and moreover an n2−o(n) blow-up in width is necessary for such a simulation. We give a deterministic, nearly logarithmic-space algorithm for mild spectral sparsification of undirected graphs. Given a weighted, undirected graph \(G\) on \(n\) vertices described by a binary string of length \(N\), an integer \(k \leq \log n \) and an error parameter \(\varepsilon > 0\), our algorithm runs in space \(\tilde{O}(k \log(N ^. w_{max}/w_{min}))\) where \(w_{max}\) and \(w_{min}\) are the maximum and minimum edge weights in \(G\), and produces a weighted graph \(H\) with \(\tilde{O}(n^{1+2/k} / \varepsilon^2)\)expected edges that spectrally approximates \(G\), in the sense of Spielmen and Teng [ST04], up to an error of \(\varepsilon\).
Our algorithm is based on a new bounded-independence analysis of Spielman and Srivastava's effective resistance based edge sampling algorithm [SS08] and uses results from recent work on space-bounded Laplacian solvers [MRSV17]. In particular, we demonstrate an inherent tradeoff (via upper and lower bounds) between the amount of (bounded) independence used in the edge sampling algorithm, denoted by \(k\) above, and the resulting sparsity that can be achieved.
%B ACM Transactions on Computation Theory %I Leibniz International Proceedings in Informatics (LIPIcs), Schloss-Dagstuhl-Leibniz-Zentrum für Informatik %G eng %U https://dl.acm.org/doi/10.1145/3637034 %0 Journal Article %D 2023 %T Complexity-theoretic implications of multicalibration %A Sílvia Casacuberta %A Cynthia Dwork %A Salil Vadhan %XWe present connections between the recent literature on multigroup fairness for prediction algorithms and classical results in computational complexity. Multiaccurate predictors are correct in expectation on each member of an arbitrary collection of pre-specified sets. Multicalibrated predictors satisfy a stronger condition: they are calibrated on each set in the collection.
Multiaccuracy is equivalent to a regularity notion for functions defined by Trevisan, Tulsiani, and Vadhan (2009). They showed that, given a class F of (possibly simple) functions, an arbitrarily complex function g can be approximated by a low-complexity function h that makes a small number of oracle calls to members of F, where the notion of approximation requires that h cannot be distinguished from g by members of F. This complexity-theoretic Regularity Lemma is known to have implications in different areas, including in complexity theory, additive number theory, information theory, graph theory, and cryptography. Starting from the stronger notion of multicalibration, we obtain stronger and more general versions of a number of applications of the Regularity Lemma, including the Hardcore Lemma, the Dense Model Theorem, and the equivalence of conditional pseudo-min-entropy and unpredictability. For example, we show that every boolean function (regardless of its hardness) has a small collection of disjoint hardcore sets, where the sizes of those hardcore sets are related to how balanced the function is on corresponding pieces of an efficient partition of the domain.
%G eng %U https://arxiv.org/abs/2312.17223 %0 Journal Article %D 2023 %T Black-box training data identification in GANs via detector networks. %A Lukman Olagoke %A Salil Vadhan %A Seth Neel %X Since their inception Generative Adversarial Networks (GANs) have been popular generative models across images, audio, video, and tabular data. In this paper we study whether given access to a trained GAN, as well as fresh samples from the underlying distribution, if it is possible for an attacker to efficiently identify if a given point is a member of the GAN's training data. This is of interest for both reasons related to copyright, where a user may want to determine if their copyrighted data has been used to train a GAN, and in the study of data privacy, where the ability to detect training set membership is known as a membership inference attack. Unlike the majority of prior work this paper investigates the privacy implications of using GANs in black-box settings, where the attack only has access to samples from the generator, rather than access to the discriminator as well. We introduce a suite of membership inference attacks against GANs in the black-box setting and evaluate our attacks on image GANs trained on the CIFAR10 dataset and tabular GANs trained on genomic data. Our most successful attack, called The Detector, involve training a second network to score samples based on their likelihood of being generated by the GAN, as opposed to a fresh sample from the distribution. We prove under a simple model of the generator that the detector is an approximately optimal membership inference attack. Across a wide range of tabular and image datasets, attacks, and GAN architectures, we find that adversaries can orchestrate non-trivial privacy attacks when provided with access to samples from the generator. At the same time, the attack success achievable against GANs still appears to be lower compared to other generative and discriminative models; this leaves the intriguing open question of whether GANs are in fact more private, or if it is a matter of developing stronger attacks. %V October %G eng %U https://arxiv.org/abs/2310.12063 %0 Conference Proceedings %B Weizhi Meng, Christian Damsgaard Jensen, Cas Cremers, and Engin Kirda, eds., Proceedings of the 30th ACM SIGAC Conference on Computer and Communications Security (CCS '23) %D 2023 %T Concurrent composition for interactive differential privacy with adaptive privacy-loss parameters %A Samuel Haney %A Michael Shoemate %A Grace Tian %A Salil P. Vadhan %A Andrew Vyrros %A Vicki Xu %A Wanrong Zhang %X In this paper, we study the concurrent composition of interactive mechanisms with adaptively chosen privacy-loss parameters. In this setting, the adversary can interleave queries to existing interac tive mechanisms, as well as create new ones. We prove that every valid privacy filter and odometer for noninteractive mechanisms extends to the concurrent composition of interactive mechanisms if privacy loss is measured using (ε, δ)-DP, f -DP, or Rényi DP of fixed order. Our results offer strong theoretical foundations for enabling full adaptivity in composing differentially private interactive mechanisms, showing that concurrency does not affect the privacy guarantees. We also provide an implementation for users to deploy
in practice.
History: Received a CCS '23 Distinguished Paper Award. Preliminary version presented as a poster at TPDP '23 and posted as: https://arxiv.org/abs/2309.05901.
%B Weizhi Meng, Christian Damsgaard Jensen, Cas Cremers, and Engin Kirda, eds., Proceedings of the 30th ACM SIGAC Conference on Computer and Communications Security (CCS '23) %I ACM %P 1949-1963 %G eng %U https://dl.acm.org/doi/10.1145/3576915.3623128 %0 Conference Proceedings %B Nicole Megow and Adam D. Smith, eds., RANDOM '23: Proceedings of the International Conference on Randomization and Computation %D 2023 %T On the power of regular and permutation branching programs. %A Chin Ho Lee %A Edward Pyne %A Salil Vadhan %XWe give new upper and lower bounds on the power of several restricted classes of arbitrary-order read-once branching programs (ROBPs) and standard-order ROBPs (SOBPs) that have received significant attention in the literature on pseudorandomness for space-bounded computation.
Regular SOBPs of length n and width w(n+1)2 can exactly simulate general SOBPs of length n and width w, and moreover an n2−o(n) blow-up in width is necessary for such a simulation.
Our result extends and simplifies prior average-case simulations (Reingold, Trevisan, and Vadhan (STOC 2006), Bogdanov, Hoza, Prakriya, and Pyne (CCC 2022)), in particular implying that weighted pseudorandom generators (Braverman, Cohen, and Garg (SICOMP 2020)) for regular SOBPs of width poly(n) or larger automatically extend to general SOBPs. Furthermore, our simulation also extends to general (even read-many) oblivious branching programs.
There exist natural functions computable by regular SOBPs of constant width that are average-case hard for permutation SOBPs of exponential width. Indeed, we show that Inner-Product mod 2 is average-case hard for arbitrary-order permutation ROBPs of exponential width.
There exist functions computable by constant-width arbitrary-order permutation ROBPs that are worst-case hard for exponential-width SOBPs.
Read-twice permutation branching programs of subexponential width can simulate polynomial-width arbitrary-order ROBPs.
%B Nicole Megow and Adam D. Smith, eds., RANDOM '23: Proceedings of the International Conference on Randomization and Computation %I Leibniz International Proceedings in Informatics (LIPIcs), Schloss Dagstuhl Leibniz-Zentrum für Informatik %V 275 %P 44:1-44:22. %G eng %U https://eccc.weizmann.ac.il/report/2023/102/ %N 44 %0 Journal Article %J PLOS Digital Health %D 2023 %T A standardised differential privacy framework for epidemiological modelling with mobile phone data %A Merveille Koissi Savi %A Akash Yadav %A Wanrong Zhang %A Navin Vembar %A Schroeder, Andrew %A Balsari, Satchit %A Caroline O. Buckee %A Salil Vadhan %A Nishant Kishore %XDuring the COVID-19 pandemic, the use of mobile phone data for monitoring human mobility patterns has become increasingly common, both to study the impact of travel restrictions on population movement and epidemiological modelling. Despite the importance of these data, the use of location information to guide public policy can raise issues of privacy and ethical use. Studies have shown that simple aggregation does not protect the privacy of an individual, and there are no universal standards for aggregation that guarantee anonymity. Newer methods, such as differential privacy, can provide statistically verifiable protection against identifiability but have been largely untested as inputs for compartment models used in infectious disease epidemiology. Our study examines the application of differential privacy as an anonymisation tool in epidemiological models, studying the impact of adding quantifiable statistical noise to mobile phone-based location data on the bias of ten common epidemiological metrics. We find that many epidemiological metrics are preserved and remain close to their non-private values when the true noise state is less than 20, in a count transition matrix, which corresponds to a privacy-less parameter ∈ = 0.05 per release. We show that differential privacy offers a robust approach to preserving individual privacy in mobility data while providing useful population-level insights for public health. Importantly, we have built a modular software pipeline to facilitate the replication and expansion of our framework.
MedArXiv version: https://www.medrxiv.org/content/10.1101/2023.03.16.23287382v1
%B PLOS Digital Health %G eng %U https://journals.plos.org/digitalhealth/article?id=10.1371/journal.pdig.0000233 %0 Conference Proceedings %B 64th IEEE Annual Symposium on Foundations of Computer Science (FOCS '23) %D 2023 %T Singular value approximation and sparsifying random walks on directed graphs %A AmirMahdi Ahmadinejad %A John Peebles %A Edward Pyne %A Aaron Sidford %XIn this paper, we introduce a new, spectral notion of approximation between directed graphs, which we call singular value (SV) approximation. SV-approximation is stronger than previous notions of spectral approximation considered in the literature, including spectral approximation of Laplacians for undirected graphs (Spielman Teng STOC 2004), standard approximation for directed graphs (Cohen et. al. STOC 2017), and unit-circle approximation for directed graphs (Ahmadinejad et. al. FOCS 2020). Further, SV approximation enjoys several useful properties not possessed by previous notions of approximation, e.g., it is preserved under products of random-walk matrices and bounded matrices.
We provide a nearly linear-time algorithm for SV-sparsifying (and hence UC-sparsifying) Eulerian directed graphs, as well as ℓ-step random walks on such graphs, for any ℓ≤poly(n). Combined with the Eulerian scaling algorithms of (Cohen et. al. FOCS 2018), given an arbitrary (not necessarily Eulerian) directed graph and a set S of vertices, we can approximate the stationary probability mass of the (S,Sc) cut in an ℓ-step random walk to within a multiplicative error of 1/polylog(n) and an additive error of 1/poly(n) in nearly linear time. As a starting point for these results, we provide a simple black-box reduction from SV-sparsifying Eulerian directed graphs to SV-sparsifying undirected graphs; such a directed-to-undirected reduction was not known for previous notions of spectral approximation.
Preliminary version posted as: "Singular value approximation and reducing directed to undirected graph sparsification": https://arxiv.org/abs/2301.13541
%B 64th IEEE Annual Symposium on Foundations of Computer Science (FOCS '23) %I IEEE %P 846-854 %G eng %U https://www.computer.org/csdl/proceedings-article/focs/2023/189400a846/1T979bqkuxG %0 Conference Proceedings %B CHI '23: Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems %D 2023 %T Don't look at the data! How differential privacy reconfigures practices of data science. %A Jayshree Sarathy %A Sophia Song %A Audrey Haque %A Tania Schlatter %A Salil Vadhan %XWe study the concurrent composition properties of interactive differentially private mechanisms, whereby an adversary can arbitrarily interleave its queries to the different mechanisms. We prove that all composition theorems for non-interactive differentially private mechanisms extend to the concurrent composition of interactive differentially private mechanisms, whenever differential privacy is measured using the hypothesis testing framework of f-DP, which captures standard (,δ)-DP as a special case. We prove the concurrent composition theorem by showing that every interactive f-DP mechanism can be simulated by interactive post-processing of a non-interactive f-DP mechanism.
In concurrent and independent work, Lyu (NeurIPS ‘22) proves a similar result to ours for (,δ)-DP, as well as a concurrent composition theorem for Rényi DP. We also provide a simple proof of Lyu’s concurrent composition theorem for Rényi DP. Lyu leaves the general case of f-DP as an open problem, which we solve in this paper.
Version History: Preliminary versions published as: https://arxiv.org/abs/2207.08335 and presented as a poster at TPDP '22.
%B STOC 2023: Proceedings of the 55th Annual ACM Symposium on Theory of Computing %I STOC %P 507-519 %G eng %U https://dl.acm.org/doi/10.1145/3564246.3585241 %0 Journal Article %J Annals of Statistics %D 2023 %T Canonical noise and private hypothesis tests. %A Jordan Awan %A Salil Vadhan %X Version/ Presentation History: Presented at CCS '21 workshop on Privacy-Preserving Machine Learning (PPML '21) and NeurIPS '21 workshop on Privacy in Machine Learning (PriML '21), November 2021. Paper posted as https://arxiv.org/abs/2108.04303 %B Annals of Statistics %V 51 %P 547-572 %G eng %U https://projecteuclid.org/journals/annals-of-statistics/volume-51/issue-2/Canonical-noise-distributions-and-private-hypothesis-tests/10.1214/23-AOS2259.short %N 2 %0 Journal Article %J Journal of Machine Learning Research %D 2023 %T Differentially private hypothesis testing for linear regression %A Daniel Alabi %A Salil Vadhan %XVersion History: Preliminary versions in NeurIPS '22, posted as arXiv:2206.14449 and presented at TPDP ‘21 (poster), IMS ‘22 (oral), and SEA ‘22 (oral). (Previously published as "Hypothesis testing for differentially private linear regression".
Abstract:
In this work, we design differentially private hypothesis tests for the following problems in the general linear model: testing a linear relationship and testing for the presence of mixtures. The majority of our hypothesis tests are based on differentially private versions of the $F$-statistic for the general linear model framework, which are uniformly most powerful unbiased in the non-private setting. We also present other tests for these problems, one of which is based on the differentially private nonparametric tests of Couch, Kazan, Shi, Bray, and Groce (CCS 2019), which is especially suited for the small dataset regime. We show that the differentially private $F$-statistic converges to the asymptotic distribution of its non-private counterpart. As a corollary, the statistical power of the differentially private $F$-statistic converges to the statistical power of the non-private $F$-statistic. Through a suite of Monte Carlo based experiments, we show that our tests achieve desired significance levels and have a high power that approaches the power of the non-private tests as we increase sample sizes or the privacy-loss parameter. We also show when our tests outperform existing methods in the literature.
%B Journal of Machine Learning Research %V 24 %P 1-50 %G eng %U https://jmlr.org/papers/v24/23-0045.html %N 361 %0 Conference Proceedings %B Proceedings on 23rd Privacy Enhancing Technologies Symposium (PoPETS ‘22) %D 2022 %T Differentially private simple linear regression %A Daniel Alabi %A Audra McMillan %A Jayshree Sarathy %A Adam Smith %A Salil Vadhan %XVersion History: Preliminary version posted as arXiv:2007.05157 [cs.LG] and presented as a poster at TPDP ‘20.
Abstract: Forthcoming.
%B Proceedings on 23rd Privacy Enhancing Technologies Symposium (PoPETS ‘22) %V 2022 (2) %P 184–204 %G eng %U https://petsymposium.org/popets/2022/popets-2022-0041.pdf %0 Conference Proceedings %B Proceedings of the 29th ACM SIGSAC Conference on Computer and Communications Security (CCS '22) %D 2022 %T Widespread underestimation of sensitivity in differentially private libraries and how to fix it %A Sílvia Casacuberta %A Michael Shoemate %A Salil Vadhan %A Connor Wagaman %X Version History: Preprint version posted as arXiv:2207.10635 [cs.CR]. %B Proceedings of the 29th ACM SIGSAC Conference on Computer and Communications Security (CCS '22) %G eng %U https://dl-acm-org.ezp-prod1.hul.harvard.edu/doi/abs/10.1145/3548606.3560708 %0 Conference Proceedings %B Proceedings of the International Conference on Randomization and Computation (RANDOM '22) %D 2022 %T Fourier growth of regular branching programs %A Chin Ho Lee %A Edward Pyne %A Salil Vadhan %XVersion History: Preliminary version posted as https://eccc.weizmann.ac.il/report/2022/034/.
Abstract: Forthcoming.
%B Proceedings of the International Conference on Randomization and Computation (RANDOM '22) %I Leibniz International Proceedings in Informatics (LIPIcs), Schloss Dagstuhl Leibniz-Zentrum für Informatik %V 245 %G eng %U https://drops.dagstuhl.de/opus/volltexte/2022/17124/pdf/LIPIcs-APPROX2.pdf %0 Conference Proceedings %B Proceedings of the SIAM Symposium on Simplicity in Algorithms (SOSA '22) %D 2022 %T Deterministic approximation of random walks via queries in graphs of unbounded size. %A Edward Pyne %A Salil Vadhan %XVersion History: Preliminary version posted as arXiv:2111.01997 [cs.CC].
Abstract: Forthcoming.
%B Proceedings of the SIAM Symposium on Simplicity in Algorithms (SOSA '22) %P 57-67 %G eng %U https://epubs.siam.org/doi/abs/10.1137/1.9781611977066.5 %0 Magazine Article %D 2022 %T Special Issue on Differential Privacy for the 2020 U.S. Census: Can we Make Data Both Private and Useful? %E Roubin Gong %E Erica L. Groshen %E Salil Vadhan %X Note: Prof. Vadhan is also the author of the editor's foreword to this issue. %B Harvard Data Science Review %V Special Issue %G eng %U https://hdsr.mitpress.mit.edu/pub/fgyf5cne/release/3 %N 2 %0 Conference Proceedings %B Proceedings of the 37th Computational Complexity Conference (CCC '22) %D 2022 %T Pseudorandomness of expander random walks for symmetric functions and permutation branching programs %A Louis Golowich %A Salil Vadhan %XVersion History: Full version (25 June 2022): https://eccc.weizmann.ac.il/report/2022/024/
Abstract: We study the pseudorandomness of random walks on expander graphs against tests computed by symmetric functions and permutation branching programs. These questions are motivated by applications of expander walks in the coding theory and derandomization literatures. A line of prior work has shown that random walks on expanders with second largest eigenvalue λ fool symmetric functions up to a O(λ) error in total variation distance, but only for the case where the vertices are labeled with symbols from a binary alphabet, and with a suboptimal dependence on the bias of the labeling. We generalize these results to labelings with an arbitrary alphabet, and for the case of binary labelings we achieve an optimal dependence on the labeling bias. We extend our analysis to unify it with and strengthen the expander-walk Chernoff bound. We then show that expander walks fool permutation branching programs up to a O(λ) error in ℓ2-distance, and we prove that much stronger bounds hold for programs with a certain structure. We also prove lower bounds to show that our results are tight. To prove our results for symmetric functions, we analyze the Fourier coefficients of the relevant distributions using linear-algebraic techniques. Our analysis for permutation branching programs is likewise linear-algebraic in nature, but also makes use of the recently introduced singular-value approximation notion for matrices (Ahmadinejad et al. 2021).
%B Proceedings of the 37th Computational Complexity Conference (CCC '22) %I Leibniz International Proceedings in Informatics (LIPIcs), Schloss Dagstuhl Leibniz-Zentrum für Informatik %V 234 %G eng %U https://drops.dagstuhl.de/opus/frontdoor.php?source_opus=16589 %0 Conference Proceedings %B Proceedings of the 27th International Computing and Combinatorics Conference (COCOON '21) %D 2021 %T Limitations of the Impagliazzo–Nisan–Wigderson pseudorandom generator against permutation branching programs. %A Edward Pyne %A Salil Vadhan %XVersion History: Preliminary version posted as ECCC TR21-108. Invited to Algorithmica Special Issue on COCOON '21.
Abstract: Forthcoming
%B Proceedings of the 27th International Computing and Combinatorics Conference (COCOON '21) %I Lecture Notes in Computer Science (Springer) %V 13025 %P 3-12 %G eng %U https://link.springer.com/chapter/10.1007/978-3-030-89543-3_1 %0 Generic %D 2021 %T Analyzing the differentially private Theil-Sen estimator for simple linear regression %A Jayshree Sarathy %A Salil Vadhan %B Poster at the 7th Workshop on the Theory and Practice of Differential Privacy (TPDP '21) – July 2021 %G eng %U https://arxiv.org/abs/2207.13289 %0 Conference Proceedings %B 19th Theory of Cryptography Conference (TCC '21) %D 2021 %T Concurrent composition of differential privacy %A Salil Vadhan %A Tianhao Wang %XVersion History: Originally published as "Monotone branching programs: pseudorandomness and circuit complexity".
Previously published as "Pseudorandom generators for read-once monotone branching programs", Electronic Colloquium on Computational Complexity (ECCC) Vol. 2021, Issue 18. Linked here: https://eccc.weizmann.ac.il/report/2021/018/
Abstract: Motivated by the derandomization of space-bounded computation, there has been a long line of work on constructing pseudorandom generators (PRGs) against various forms of read-once branching programs (ROBPs), with a goal of improving the \(O(\log^2n)\) seed length of Nisan’s classic construction to the optimal \(O(\log n)\).
In this work, we construct an explicit PRG with seed length \(\tilde{O}(\log n)\) for constant-width ROBPs that are monotone, meaning that the states at each time step can be ordered so that edges with the same labels never cross each other. Equivalently, for each fixed input, the transition functions are a monotone function of the state. This result is complementary to a line of work that gave PRGs with seed length \(O(\log n)\) for (ordered) permutation ROBPs of constant width, since the monotonicity constraint can be seen as the “opposite” of the permutation constraint.
Our PRG also works for monotone ROBPs that can read the input bits in any order, which are strictly more powerful than read-once \(\mathsf{AC^0}\). Our PRG achieves better parameters (in terms of the dependence on the depth of the circuit) than the best previous pseudorandom generator for read-once \(\mathsf{AC^0}\), due to Doron, Hatami, and Hoza.
Our pseudorandom generator construction follows Ajtai and Wigderson’s approach of iterated pseudorandom restrictions. We give a randomness-efficient width-reduction process which proves that the branching program simplifies to an \(O(\log n)\)-junta after only \(O(\log \log n)\) independent applications of the Forbes-Kelley pseudorandom restrictions.
%B APPROX/ RANDOM 2021 %7 207 %I Leibniz International Proceedings in Informatics (LIPIcs), Schloss Dagstuhl Leibniz-Zentrum für Informatik %V 2021 %P 58:1-58:21 %G eng %U https://drops.dagstuhl.de/opus/volltexte/2021/14751/ %N 18 %0 Conference Proceedings %B 36th Annual Computational Complexity Conference (CCC '21) %D 2021 %T Pseudodistributions that beat all pseudorandom generators %A Edward Pyne %A Salil Vadhan %XVersion History: Full Version posted as ECC TR21-019. Invited to Theory of Computing Special Issue on CCC '21.
Abstract:
A recent paper of Braverman, Cohen, and Garg (STOC 2018) introduced the concept of a pseudorandom pseudodistribution generator (PRPG), which amounts to a pseudorandom generator (PRG) whose outputs are accompanied with real coefficients that scale the acceptance probabilities of any potential distinguisher. They gave an explicit construction of PRPGs for ordered branching programs whose seed length has a better dependence on the error parameter  than the classic PRG construction of Nisan (STOC 1990 and Combinatorica 1992).
than the classic PRG construction of Nisan (STOC 1990 and Combinatorica 1992).
In this work, we give an explicit construction of PRPGs that achieve parameters that are impossible to achieve by a PRG. In particular, we construct a PRPG for ordered permutation branching programs of unbounded width with a single accept state that has seed length \(\tilde{O}(\log^{3/2}n)\) for error parameter \( \epsilon = 1/ \mathrm{poly}(n)\), where \(n\) is the input length. In contrast, recent work of Hoza et al. (ITCS 2021) shows that any PRG for this model requires seed length \( \Omega(\log^2n)\) to achieve error \( \epsilon = 1/ \mathrm{poly}(n)\).
As a corollary, we obtain explicit PRPGs with seed length \(\tilde{O}(\log^{3/2}n)\) and error \( \epsilon = 1/ \mathrm{poly}(n)\) for ordered permutation branching programs of width \(w = \mathrm{poly}(n) \)with an arbitrary number of accept states. Previously, seed length \(o(\log^2n)\) was only known when both the width and the reciprocal of the error are subpolynomial, i.e. \(w= n^{o(1)} \) and \(\epsilon = 1/n^{o(1)}\)(Braverman, Rao, Raz, Yehudayoff, FOCS 2010 and SICOMP 2014).
The starting point for our results are the recent space-efficient algorithms for estimating random-walk probabilities in directed graphs by Ahmadenijad, Kelner, Murtagh, Peebles, Sidford, and Vadhan (FOCS 2020), which are based on spectral graph theory and space-efficient Laplacian solvers. We interpret these algorithms as giving PRPGs with large seed length, which we then derandomize to obtain our results. We also note that this approach gives a simpler proof of the original result of Braverman, Cohen, and Garg, as independently discovered by Cohen, Doron, Renard, Sberlo, and Ta-Shma (personal communication, January 2021).
Version History:
Preliminary version posted on ECCC TR20-138 (PDF version attached as ECCC 2020).
Talks: The ITCS talk for this paper, presented by Edward Pyne, is currently available on YouTube; click the embedded link to view.
We prove that the Impagliazzo-Nisan-Wigderson [Impagliazzo et al., 1994] pseudorandom generator (PRG) fools ordered (read-once) permutation branching programs of unbounded width with a seed length of \(\tilde{O} (\log d + \log n ⋅ \log(1/\epsilon))\), assuming the program has only one accepting vertex in the final layer. Here, \(n\) is the length of the program, \(d\) is the degree (equivalently, the alphabet size), and \(\epsilon\) is the error of the PRG. In contrast, we show that a randomly chosen generator requires seed length \(\Omega (n \log d)\) to fool such unbounded-width programs. Thus, this is an unusual case where an explicit construction is "better than random."
Except when the program’s width \(w\) is very small, this is an improvement over prior work. For example, when \(w = \mathrm{poly} (n)\) and \(d = 2\), the best prior PRG for permutation branching programs was simply Nisan’s PRG [Nisan, 1992], which fools general ordered branching programs with seed length \(O (\log (wn/\epsilon) \log n)\). We prove a seed length lower bound of \(\tilde{\Omega} (\log d + \log n ⋅ \log(1/\epsilon)) \)for fooling these unbounded-width programs, showing that our seed length is near-optimal. In fact, when\( \epsilon ≤ 1/\log n\), our seed length is within a constant factor of optimal. Our analysis of the INW generator uses the connection between the PRG and the derandomized square of Rozenman and Vadhan [Rozenman and Vadhan, 2005] and the recent analysis of the latter in terms of unit-circle approximation by Ahmadinejad et al. [Ahmadinejad et al., 2020].
%B 12th Innovations in Theoretical Computer Science (ITCS '21) %I Leibniz International Proceedings in Informatics (LIPIcs) %V 185 %P 1-20 %G eng %U https://drops.dagstuhl.de/opus/frontdoor.php?source_opus=13546 %N 7 %0 Book Section %B Beyond the Worst-Case Analysis of Algorithms (Tim Roughgarden, ed.) %D 2021 %T When simple hash functions suffice. %A Kai-Min Chung %A Michael Mitzenmacher %A Salil Vadhan %B Beyond the Worst-Case Analysis of Algorithms (Tim Roughgarden, ed.) %I Cambridge University Press %C Cambridge, UK %G eng %U https://doi.org/10.1017/9781108637435.033 %0 Journal Article %J Theory of Computing Special Issue on APPROX-RANDOM '19 %D 2021 %T Deterministic approximation of random walks in small space %A Jack Murtagh %A Omer Reingold %A Aaron Sidford %A Salil Vadhan %XWe give a deterministic, nearly logarithmic-space algorithm that given an undirected graph \(G\), a positive integer \(r\), and a set \(S\) of vertices, approximates the conductance of \(S\) in the \(r\)-step random walk on \(G\) to within a factor of \(1+ϵ\), where \(ϵ > 0\) is an arbitrarily small constant. More generally, our algorithm computes an \(ϵ\)-spectral approximation to the normalized Laplacian of the \(r\)-step walk. Our algorithm combines the derandomized square graph operation (Rozenman and Vadhan, 2005), which we recently used for solving Laplacian systems in nearly logarithmic space (Murtagh, Reingold, Sidford, and Vadhan, 2017), with ideas from (Cheng, Cheng, Liu, Peng, and Teng, 2015), which gave an algorithm that is time-efficient (while ours is space-efficient) and randomized (while ours is deterministic) for the case of even \(r\) (while ours works for all \(r\)). Along the way, we provide some new results that generalize technical machinery and yield improvements over previous work. First, we obtain a nearly linear-time randomized algorithm for computing a spectral approximation to the normalized Laplacian for odd \(r\). Second, we define and analyze a generalization of the derandomized square for irregular graphs and for sparsifying the product of two distinct graphs. As part of this generalization, we also give a strongly explicit construction of expander graphs of every size.
%B Theory of Computing Special Issue on APPROX-RANDOM '19 %I Leibniz International Proceedings in Informatics (LIPIcs) %C Cambridge, Massachusetts (MIT) %V 17(4) %P 1-35 %G eng %U http://theoryofcomputing.org/articles/v017a004/ %0 Book Section %B Using Administrative Data for Research and Evidence-based Policy – A Handbook %D 2020 %T Designing Access with Differential Privacy %A Micah Altman %A Kobbi Nissim %A Salil Vadhan %A Alexandra Wood %XWebinar: https://www.youtube.com/watch?v=cOu-sTV8J2M
This chapter explains how administrative data containing personal information can be collected, analyzed, and published in a way that ensures the individuals in the data will be afforded the strong protections of differential privacy.
It is intended as a practical resource for government agencies and research organizations interested in exploring the possibility of implementing tools for differentially private data sharing and analysis. Using intuitive examples rather than the mathematical formalism used in other guides, this chapter introduces the differential privacy definition and the risks it was developed to address. The text employs modern privacy frameworks to explain how to determine whether the use of differential privacy is an appropriate solution in a given setting. It also discusses the design considerations one should take into account when implementing differential privacy. This discussion incorporates a review of real-world implementations, including tools designed for tiered access systems combining differential privacy with other disclosure controls presented in this Handbook, such as consent mechanisms, data use agreements, and secure environments.
Differential privacy technology has passed a preliminary transition from being the subject of academic work to initial implementations by large organizations and high-tech companies that have the expertise to develop and implement customized differentially private methods. With a growing collection of software packages for generating differentially private releases from summary statistics to machine learning models, differential privacy is now transitioning to being usable more widely and by smaller organizations.
%B Using Administrative Data for Research and Evidence-based Policy – A Handbook %I Abdul Latif Jameel Poverty Action Lab (J-PAL). %C Cambridge, United States %P 173-242 %G eng %U https://admindatahandbook.mit.edu/book/v1.0/index.html %0 Generic %D 2020 %T A programming framework for OpenDP %A Michael Hay %A Marco Gaboardi %A Salil Vadhan %XVersion History: Original version released as a Working Paper for the May 2020 OpenDP Community Meeting (version attached as MAY 2020.pdf, and accessible online at https://projects.iq.harvard.edu/files/opendp/files/opendp_programming_framework_11may2020_1_01.pdf).
Talks: View a talk on this paper presented by Marco Gaboardi and Michael Hay at the 2020 OpenDP Community Meeting.
Subsequently presented as a poster at TPDP 2020 (attached as TPDP2020.pdf).
In this working paper, we propose a programming framework for the library of differentially private algorithms that will be at the core of the OpenDP open-source software project, and recommend programming languages in which to implement the framework.
%B 6th Workshop on the Theory and Practice of Differential Privacy (TPDP 2020) %G eng %U https://projects.iq.harvard.edu/files/opendp/files/opendp_programming_framework_11may2020_1_01.pdf %0 Manuscript %D 2020 %T The OpenDP White Paper %A Team OpenDP %XOpenDP is led by Faculty Directors Gary King and Salil Vadhan and an Executive Committee at Harvard University, funded in part by a grant from the Sloan Foundation. Its efforts so far have included implementing a differentially private curator application in collaboration with Microsoft, and developing a framework for a community-driven OpenDP Commons through the work of an Ad Hoc Design Committee including external experts. Going forward, the project plans to engage with a wide community of stakeholders, establish partnerships with a wide variety of groups from industry, academia, and government, and adopt increasing levels of community governance.
%G eng %U https://projects.iq.harvard.edu/files/opendp/files/opendp_white_paper_11may2020.pdf %0 Journal Article %J arXiv: 2010.05586 [cs.CR] %D 2020 %T Inaccessible entropy I: Inaccessible entropy generators and statistically hiding commitments from one-way functions %A Iftach Haitner %A Omer Reingold %A Salil Vadhan %A Hoeteck Wee %XVersion History: Full version of part of an STOC 2009 paper.
We put forth a new computational notion of entropy, measuring the (in)feasibility of sampling high-entropy strings that are consistent with a given generator. Specifically, the \(i\)'th output block of a generator \(\mathsf{G}\) has accessible entropy at most \(k\) if the following holds: when conditioning on its prior coin tosses, no polynomial-time strategy \(\mathsf{\widetilde{G}}\) can generate valid output for \(\mathsf{G}\)'s \(i \)'th output block with entropy greater than \(k\). A generator has inaccessible entropy if the total accessible entropy (summed over the blocks) is noticeably smaller than the real entropy of \(\mathsf{G}\)'s output.
As an application of the above notion, we improve upon the result of Haitner, Nguyen, Ong, Reingold, and Vadhan [Sicomp '09], presenting a much simpler and more efficient construction of statistically hiding commitment schemes from arbitrary one-way functions.
%B arXiv: 2010.05586 [cs.CR] %G eng %U https://arxiv.org/abs/2010.05586 %0 Conference Proceedings %B 61st Annual IEEE Symposium on the Foundations of Computer Science (FOCS 2020) %D 2020 %T High-precision estimation of random walks in small space %A AmirMahdi Ahmadinejad %A Kelner, Jonathan %A Jack Murtagh %A John Peebles %A Aaron Sidford %A Salil Vadhan %XVersion History: published earlier in Henri Gilbert, ed., Advances in Cryptology—EUROCRYPT ‘10, Lecture Notes on Computer Science, as "Universal one-way hash functions via inaccessible entropy":
https://link.springer.com/chapter/10.1007/978-3-642-13190-5_31
This paper revisits the construction of Universal One-Way Hash Functions (UOWHFs) from any one-way function due to Rompel (STOC 1990). We give a simpler construction of UOWHFs, which also obtains better efficiency and security. The construction exploits a strong connection to the recently introduced notion of inaccessible entropy (Haitner et al. STOC 2009). With this perspective, we observe that a small tweak of any one-way function \(f\) is already a weak form of a UOWHF: Consider \(F(x', i)\) that outputs the \(i\)-bit long prefix of \(f(x)\). If \(F\) were a UOWHF then given a random \(x\) and \(i\) it would be hard to come up with \(x' \neq x\) such that \(F(x, i) = F(x', i)\). While this may not be the case, we show (rather easily) that it is hard to sample \(x'\) with almost full entropy among all the possible such values of \(x'\). The rest of our construction simply amplifies and exploits this basic property.
With this and other recent works, we have that the constructions of three fundamental cryptographic primitives (Pseudorandom Generators, Statistically Hiding Commitments and UOWHFs) out of one-way functions are to a large extent unified. In particular, all three constructions rely on and manipulate computational notions of entropy in similar ways. Pseudorandom Generators rely on the well-established notion of pseudoentropy, whereas Statistically Hiding Commitments and UOWHFs rely on the newer notion of inaccessible entropy.
%B Theory of Computing %I Springer-Verlag %V 16 %P 1-55 %G eng %U http://theoryofcomputing.org/articles/v016a008/ %N 8 %0 Journal Article %J Journal of Cryptology %D 2020 %T PCPs and the hardness of generating synthetic data %A Jon Ullman %A Salil Vadhan %XVersion History: Full version posted as ECCC TR10-017.
Published earlier in Yuval Ishai, ed., Proceedings of the 8th IACR Theory of Cryptography Conference (TCC ‘11), Lecture Notes on Computer Science. Springer-Verlag, Publishers: Vol. 5978, pp. 572-587. https://link.springer.com/chapter/10.1007/978-3-642-19571-6_24
Invited to J. Cryptology selected papers from TCC 2011.
Assuming the existence of one-way functions, we show that there is no polynomial-time, differentially private algorithm \(\mathcal{A}\) that takes a database \(D ∈ ({0, 1}^d)^n\) and outputs a “synthetic database” \(\hat{D}\) all of whose two-way marginals are approximately equal to those of \(D\). (A two-way marginal is the fraction of database rows \(x ∈ {0, 1}^d\) with a given pair of values in a given pair of columns.) This answers a question of Barak et al. (PODS ‘07), who gave an algorithm running in time \(\mathrm{poly} (n, 2^d)\).
Our proof combines a construction of hard-to-sanitize databases based on digital signatures (by Dwork et al., STOC ‘09) with encodings based on probabilistically checkable proofs.
We also present both negative and positive results for generating “relaxed” synthetic data, where the fraction of rows in \(D\) satisfying a predicate \(c\) are estimated by applying \(c\) to each row of \(\hat{D}\) and aggregating the results in some way.
%B Journal of Cryptology %I Springer-Verlag %V 33 %P 2078-2112 %G eng %U https://link.springer.com/article/10.1007/s00145-020-09363-y %0 Journal Article %J ACM Transactions on Economics and Computation %D 2020 %T Privacy games %A Yiling Chen %A Or Sheffet %A Salil Vadhan %XVersion History:
Previously published as: Yiling Chen, Or Sheffet, and Salil Vadhan. Privacy games. In Proceedings of the 10th International Conference on Web and Internet Economics (WINE ‘14), volume 8877 of Lecture Notes in Computer Science, pages 371–385. Springer-Verlag, 14–17 December 2014. (WINE Publisher's Version linked here: https://link.springer.com/chapter/10.1007/978-3-319-13129-0_30); PDF attached as WINE2014.
The problem of analyzing the effect of privacy concerns on the behavior of selfish utility-maximizing agents has received much attention lately. Privacy concerns are often modeled by altering the utility functions of agents to consider also their privacy loss. Such privacy aware agents prefer to take a randomized strategy even in very simple games in which non-privacy aware agents play pure strategies. In some cases, the behavior of privacy aware agents follows the framework of Randomized Response, a well-known mechanism that preserves differential privacy.
Our work is aimed at better understanding the behavior of agents in settings where their privacy concerns are explicitly given. We consider a toy setting where agent A, in an attempt to discover the secret type of agent B, offers B a gift that one type of B agent likes and the other type dislikes. As opposed to previous works, B's incentive to keep her type a secret isn't the result of "hardwiring" B's utility function to consider privacy, but rather takes the form of a payment between B and A. We investigate three different types of payment functions and analyze B's behavior in each of the resulting games. As we show, under some payments, B's behavior is very different than the behavior of agents with hardwired privacy concerns and might even be deterministic. Under a different payment we show that B's BNE strategy does fall into the framework of Randomized Response.
In this survey, we present several computational analogues of entropy and illustrate how they are useful for constructing cryptographic primitives. Specifically, we focus on constructing pseudorandom generators and statistically hiding commitments from arbitrary one-way functions, and demonstrate that:
The constructions we present (which are from the past decade) are much simpler and more efficient than the original ones, and are based entirely on natural manipulations of new notions of computational entropy. The two constructions are "dual" to each other, whereby the construction of pseudorandom generators relies on a form of computational entropy ("pseudoentropy") being larger than the real entropy, while the construction of statistically hiding commitments relies on a form of computational entropy ("accessible entropy") being smaller than the real entropy. Beyond that difference, the two constructions share a common structure, using a very similar sequence of manipulations of real and computational entropy. As a warmup, we also "deconstruct" the classic construction of pseudorandom generators from one-way permutations using the modern language of computational entropy.
This survey is written in honor of Shafi Goldwasser and Silvio Micali.
%B Providing Sound Foundations for Cryptography: On the Work of Shafi Goldwasser and Silvio Micali (Oded Goldreich, Ed.) %I ACM %P 693-726 %G eng %U https://dl.acm.org/doi/10.1145/3335741.3335767 %0 Journal Article %J Journal of Privacy and Confidentiality %D 2019 %T Differential privacy on finite computers %A Victor Balcer %A Salil Vadhan %X
Version History:
Also presented at TPDP 2017; preliminary version posted as arXiv:1709.05396 [cs.DS].
2018: Published in Anna R. Karlin, editor, 9th Innovations in Theoretical Computer Science Conference (ITCS 2018), volume 94 of Leibniz International Proceedings in Informatics (LIPIcs), pp 43:1-43:21. http://drops.dagstuhl.de/opus/frontdoor.php?source_opus=8353
We consider the problem of designing and analyzing differentially private algorithms that can be implemented on discrete models of computation in strict polynomial time, motivated by known attacks on floating point implementations of real-arithmetic differentially private algorithms (Mironov, CCS 2012) and the potential for timing attacks on expected polynomial-time algorithms. As a case study, we examine the basic problem of approximating the histogram of a categorical dataset over a possibly large data universe \(X\). The classic Laplace Mechanism (Dwork, McSherry, Nissim, Smith, TCC 2006 and J. Privacy & Confidentiality 2017) does not satisfy our requirements, as it is based on real arithmetic, and natural discrete analogues, such as the Geometric Mechanism (Ghosh, Roughgarden, Sundarajan, STOC 2009 and SICOMP 2012), take time at least linear in \(|X|\), which can be exponential in the bit length of the input.
In this paper, we provide strict polynomial-time discrete algorithms for approximate histograms whose simultaneous accuracy (the maximum error over all bins) matches that of the Laplace Mechanism up to constant factors, while retaining the same (pure) differential privacy guarantee. One of our algorithms produces a sparse histogram as output. Its “per-bin accuracy” (the error on individual bins) is worse than that of the Laplace Mechanism by a factor of \(\log |X|\), but we prove a lower bound showing that this is necessary for any algorithm that produces a sparse histogram. A second algorithm avoids this lower bound, and matches the per-bin accuracy of the Laplace Mechanism, by producing a compact and efficiently computable representation of a dense histogram; it is based on an \((n + 1)\)-wise independent implementation of an appropriately clamped version of the Discrete Geometric Mechanism.
%B Journal of Privacy and Confidentiality %I ITCS %C Dagstuhl, Germany, 2018. Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik. %V 9 %G eng %U https://journalprivacyconfidentiality.org/index.php/jpc/article/view/679 %N 2 %0 Conference Paper %B Advances in Cryptology: CRYPTO 2019, A. Boldyreva and D. Micciancio, (Eds) %D 2019 %T Unifying computational entropies via Kullback-Leibler divergence %A Rohit Agrawal %A Yi-Hsiu Chen %A Thibaut Horel %A Salil Vadhan %XVersion History: Preliminary versions in EUROCRYPT ‘13 and Cryptology ePrint report 2013/125.
Bellare, Boldyreva, and O’Neill (CRYPTO '07) initiated the study of deterministic public-key encryption as an alternative in scenarios where randomized encryption has inherent drawbacks. The resulting line of research has so far guaranteed security only for adversarially-chosen plaintext distributions that are independent of the public key used by the scheme. In most scenarios, however, it is typically not realistic to assume that adversaries do not take the public key into account when attacking a scheme.
We show that it is possible to guarantee meaningful security even for plaintext distributions that depend on the public key. We extend the previously proposed notions of security, allowing adversaries to adaptively choose plaintext distributions after seeing the public key, in an interactive manner. The only restrictions we make are that: (1) plaintext distributions are unpredictable (as is essential in deterministic public-key encryption), and (2) the number of plaintext distributions from which each adversary is allowed to adaptively choose is upper bounded by \(2^p\), where \(p\) can be any predetermined polynomial in the security parameter. For example, with \(p=0\) we capture plaintext distributions that are independent of the public key, and with \(p=0(s \log s)\) we capture, in particular, all plaintext distributions that are samplable by circuits of size \(s\).
Within our framework we present both constructions in the random-oracle model based on any public-key encryption scheme, and constructions in the standard model based on lossy trapdoor functions (thus, based on a variety of number-theoretic assumptions). Previously known constructions heavily relied on the independence between the plaintext distributions and the public key for the purposes of randomness extraction. In our setting, however, randomness extraction becomes significantly more challenging once the plaintext distributions and the public key are no longer independent. Our approach is inspired by research on randomness extraction from seed-dependent distributions. Underlying our approach is a new generalization of a method for such randomness extraction, originally introduced by Trevisan and Vadhan (FOCS '00) and Dodis (PhD Thesis, MIT, '00).
%B Journal of Cryptology %V 31 %P 1012-1063 %G eng %U https://link.springer.com/article/10.1007/s00145-018-9287-y %N 4 %0 Journal Article %J SIAM Journal on Computing, Special Issue on STOC '14 %D 2018 %T Fingerprinting codes and the price of approximate differential privacy %A Mark Bun %A Jonathan Ullman %A Salil Vadhan %XVersion History: Special Issue on STOC ‘14. Preliminary versions in STOC ‘14 and arXiv:1311.3158 [cs.CR].
We show new information-theoretic lower bounds on the sample complexity of (ε, δ)- differentially private algorithms that accurately answer large sets of counting queries. A counting query on a database \(D ∈ (\{0, 1\}^d)^n\) has the form “What fraction of the individual records in the database satisfy the property \(q\)?” We show that in order to answer an arbitrary set \(Q\) of \(\gg d/ \alpha^2\) counting queries on \(D\) to within error \(±α\) it is necessary that \(n ≥ \tilde{Ω}(\sqrt{d} \log |Q|/α^2ε)\). This bound is optimal up to polylogarithmic factors, as demonstrated by the private multiplicative weights algorithm (Hardt and Rothblum, FOCS’10). In particular, our lower bound is the first to show that the sample complexity required for accuracy and (ε, δ)-differential privacy is asymptotically larger than what is required merely for accuracy, which is \(O(\log |Q|/α^2 )\). In addition, we show that our lower bound holds for the specific case of \(k\)-way marginal queries (where \(|Q| = 2^k \binom{d}{k}\) ) when \(\alpha\) is not too small compared to d (e.g., when \(\alpha\) is any fixed constant). Our results rely on the existence of short fingerprinting codes (Boneh and Shaw, CRYPTO’95; Tardos, STOC’03), which we show are closely connected to the sample complexity of differentially private data release. We also give a new method for combining certain types of sample-complexity lower bounds into stronger lower bounds.
%B SIAM Journal on Computing, Special Issue on STOC '14 %V 47 %P 1888-1938 %G eng %U https://epubs.siam.org/doi/abs/10.1137/15M1033587?mobileUi=0& %N 5 %0 Journal Article %J Theory of Computing %D 2018 %T The complexity of computing the optimal composition of differential privacy %A Jack Murtagh %A Salil Vadhan %XVersion History: Full version posted on CoRR, abs/1507.03113, July 2015. Additional version published in Proceedings of the 13th IACR Theory of Cryptography Conference (TCC '16-A).
In the study of differential privacy, composition theorems (starting with the original paper of Dwork, McSherry, Nissim, and Smith (TCC '06)) bound the degradation of privacy when composing several differentially private algorithms. Kairouz, Oh, and Viswanath (ICML '15) showed how to compute the optimal bound for composing \(k\) arbitrary (\(\epsilon\),\(\delta\))- differentially private algorithms. We characterize the optimal composition for the more general case of \(k\) arbitrary (\(\epsilon_1\) , \(\delta_1\) ), . . . , (\(\epsilon_k\) , \(\delta_k\) )-differentially private algorithms where the privacy parameters may differ for each algorithm in the composition. We show that computing the optimal composition in general is \(\#\)P-complete. Since computing optimal composition exactly is infeasible (unless FP\(=\)\(\#\)P), we give an approximation algorithm that computes the composition to arbitrary accuracy in polynomial time. The algorithm is a modification of Dyer’s dynamic programming approach to approximately counting solutions to knapsack problems (STOC '03).
%B Theory of Computing %I Lecture Notes in Computer Science, Springer-Verlag %V 14 %P 1-35 %G eng %U https://theoryofcomputing.org/articles/v014a008/ %0 Conference Paper %B Anna R. Karlin, editor, 9th Innovations in Theoretical Computer Science Conference (ITCS 2018), volume 94 of Leibniz International Proceedings in Informatics (LIPIcs) %D 2018 %T Finite sample differentially private confidence intervals %A Vishesh Karwa %A Salil Vadhan %XVersion History: Also presented at TPDP 2017. Preliminary version posted as arXiv:1711.03908 [cs.CR].
We study the problem of estimating finite sample confidence intervals of the mean of a normal population under the constraint of differential privacy. We consider both the known and unknown variance cases and construct differentially private algorithms to estimate confidence intervals. Crucially, our algorithms guarantee a finite sample coverage, as opposed to an asymptotic coverage. Unlike most previous differentially private algorithms, we do not require the domain of the samples to be bounded. We also prove lower bounds on the expected size of any differentially private confidence set showing that our the parameters are optimal up to polylogarithmic factors.
%B Anna R. Karlin, editor, 9th Innovations in Theoretical Computer Science Conference (ITCS 2018), volume 94 of Leibniz International Proceedings in Informatics (LIPIcs) %I ITCS %C Dagstuhl, Germany, 2018. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik. %P 44:1-44:9 %G eng %U http://drops.dagstuhl.de/opus/volltexte/2018/8344/ %0 Manuscript %D 2018 %T Usable differential privacy: A case study with PSI %A Jack Murtagh %A Taylor, Kathryn %A George Kellaris %A Salil P. Vadhan %XVersion History: v1, 11 September 2018 https://arxiv.org/abs/1809.04103
Differential privacy is a promising framework for addressing the privacy concerns in sharing sensitive datasets for others to analyze. However differential privacy is a highly technical area and current deployments often require experts to write code, tune parameters, and optimize the trade-off between the privacy and accuracy of statistical releases. For differential privacy to achieve its potential for wide impact, it is important to design usable systems that enable differential privacy to be used by ordinary data owners and analysts. PSI is a tool that was designed for this purpose, allowing researchers to release useful differentially private statistical information about their datasets without being experts in computer science, statistics, or privacy. We conducted a thorough usability study of PSI to test whether it accomplishes its goal of usability by non-experts. The usability test illuminated which features of PSI are most user-friendly and prompted us to improve aspects of the tool that caused confusion. The test also highlighted some general principles and lessons for designing usable systems for differential privacy, which we discuss in depth.
%B arXiv %G eng %U https://arxiv.org/abs/1809.04103 %N 1809.04103 [cs.CR] %0 Conference Paper %B 33rd Computational Complexity Conference (CCC 2018) %D 2018 %T A tight lower bound for entropy flattening %A Yi-Hsiu Chen %A Mika Goos %A Salil P. Vadhan %A Jiapeng Zhang %XVersion History: Preliminary version posted as ECCC TR18-119.
We study entropy flattening: Given a circuit \(C_X\) implicitly describing an n-bit source \(X\) (namely, \(X\) is the output of \(C_X \) on a uniform random input), construct another circuit \(C_Y\) describing a source \(Y\) such that (1) source \(Y\) is nearly flat (uniform on its support), and (2) the Shannon entropy of \(Y\) is monotonically related to that of \(X\). The standard solution is to have \(C_Y\) evaluate \(C_X\) altogether \(\Theta(n^2)\) times on independent inputs and concatenate the results (correctness follows from the asymptotic equipartition property). In this paper, we show that this is optimal among black-box constructions: Any circuit \(C_Y\) for entropy flattening that repeatedly queries \(C_X\) as an oracle requires \(\Omega(n^2)\)queries.
Entropy flattening is a component used in the constructions of pseudorandom generators and other cryptographic primitives from one-way functions [12, 22, 13, 6, 11, 10, 7, 24]. It is also used in reductions between problems complete for statistical zero-knowledge [19, 23, 4, 25]. The \(\Theta(n^2)\) query complexity is often the main efficiency bottleneck. Our lower bound can be viewed as a step towards proving that the current best construction of pseudorandom generator from arbitrary one-way functions by Vadhan and Zheng (STOC 2012) has optimal efficiency.
%B 33rd Computational Complexity Conference (CCC 2018) %I Leibniz International Proceedings in Informatics (LIPIcs) %C Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik %V 102 %P 23:21-23:28 %G eng %U http://drops.dagstuhl.de/opus/frontdoor.php?source_opus=8866 %0 Journal Article %J Vanderbilt Journal of Entertainment & Technology Law %D 2018 %T Differential privacy: A primer for a non-technical audience %A Alexandra Wood %A Micah Altman %A Aaron Bembenek %A Mark Bun %A Marco Gaboardi %A James Honaker %A Kobbi Nissim %A David R. OBrien %A Thomas Steinke %A Salil Vadhan %XVersion History: Preliminary version workshopped at PLSC 2017.
Differential privacy is a formal mathematical framework for quantifying and managing privacy risks. It provides provable privacy protection against a wide range of potential attacks, including those currently unforeseen. Differential privacy is primarily studied in the context of the collection, analysis, and release of aggregate statistics. These range from simple statistical estimations, such as averages, to machine learning. Tools for differentially private analysis are now in early stages of implementation and use across a variety of academic, industry, and government settings. Interest in the concept is growing among potential users of the tools, as well as within legal and policy communities, as it holds promise as a potential approach to satisfying legal requirements for privacy protection when handling personal information. In particular, differential privacy may be seen as a technical solution for analyzing and sharing data while protecting the privacy of individuals in accordance with existing legal or policy requirements for de-identification or disclosure limitation.
This primer seeks to introduce the concept of differential privacy and its privacy implications to non-technical audiences. It provides a simplified and informal, but mathematically accurate, description of differential privacy. Using intuitive illustrations and limited mathematical formalism, it discusses the definition of differential privacy, how differential privacy addresses privacy risks, how differentially private analyses are constructed, and how such analyses can be used in practice. A series of illustrations is used to show how practitioners and policymakers can conceptualize the guarantees provided by differential privacy. These illustrations are also used to explain related concepts, such as composition (the accumulation of risk across multiple analyses), privacy loss parameters, and privacy budgets. This primer aims to provide a foundation that can guide future decisions when analyzing and sharing statistical data about individuals, informing individuals about the privacy protection they will be afforded, and designing policies and regulations for robust privacy protection.
%B Vanderbilt Journal of Entertainment & Technology Law %V 21 %P 209-275 %G eng %U http://www.jetlaw.org/journal-archives/volume-21/volume-21-issue-1/differential-privacy-a-primer-for-a-non-technical-audience/ %N 1 %0 Report %D 2017 %T Comments on the City of Seattle Open Data Risk Assessment %A Alexandra Wood %A Micah Altman %A Suso Baleato %A Salil Vadhan %X The transparency goals of the open data movement serve important social, economic, and democratic functions in cities like Seattle. At the same time, some municipal datasets about the city and its citizens’ activities carry inherent risks to individual privacy when shared publicly. In 2016, the City of Seattle declared in its Open Data Policy that the city’s data would be “open by preference,” except when doing so may affect individual privacy. To ensure its Open Data program effectively protects individuals, Seattle committed to performing an annual risk assessment and tasked the Future of Privacy Forum (FPF) with creating and deploying an initial privacy risk assessment methodology for open data.This Draft Report provides tools and guidance to the City of Seattle and other municipalities navigating the complex policy, operational, technical, organizational, and ethical standards that support privacyprotective open data programs. Although there is a growing body of research on open data privacy, open data managers and departmental data owners need to be able to employ a standardized methodology for assessing the privacy risks and benefits of particular datasets internally, without a bevy of expert statisticians, privacy lawyers, or philosophers. By following a flexible, risk-based assessment process, the City of Seattle – and other municipal open data programs – can maximize the utility and openness of civic data while minimizing privacy risks to individuals and community concerns about ethical challenges, fairness, and equity.This Draft Report first describes inherent privacy risks in an open data landscape, with an emphasis on potential harms related to re-identification, data quality, and fairness. Accompanying this, the Draft Report includes a Model Open Data Benefit Risk Analysis (MODBRA). The model template evaluates the types of data contained in a proposed open dataset, the potential benefits – and concomitant risks – of releasing the dataset publicly, and strategies for effective de-identification and risk mitigation. This holistic assessment guides city officials to determine whether to release the dataset openly, in a limited access environment, or to withhold it from publication (absent countervailing public policy considerations). The Draft Report methodology builds on extensive work done in this field by experts at the National Institute of Standards and Technology, the University of Washington, the Berkman Klein Center for Internet & Society at Harvard University, and others, and adapts existing frameworks to the unique challenges faced by cities as local governments, technological system integrators, and consumer facing service providers. %G eng %U https://fpf.org/wp-content/uploads/2018/01/Wood-Altman-Baleato-Vadhan_Comments-on-FPF-Seattle-Open-Data-Draft-Report.pdf %0 Book Section %B Tutorials on the Foundations of Cryptography %D 2017 %T The Many Entropies in One-way Functions %A Iftach Haitner %A Salil Vadhan %XVersion History:
Earlier versions: May 2017: ECCC TR 17-084
Dec. 2017: ECCC TR 17-084 (revised)
Computational analogues of information-theoretic notions have given rise to some of the most interesting phenomena in the theory of computation. For example, computational indistinguishability, Goldwasser and Micali [9], which is the computational analogue of statistical distance, enabled the bypassing of Shannon’s impossibility results on perfectly secure encryption, and provided the basis for the computational theory of pseudorandomness. Pseudoentropy, Håstad, Impagliazzo, Levin, and Luby [17], a computational analogue of entropy, was the key to the fundamental result establishing the equivalence of pseudorandom generators and one-way functions, and has become a basic concept in complexity theory and cryptography.
This tutorial discusses two rather recent computational notions of entropy, both of which can be easily found in any one-way function, the most basic cryptographic primitive. The first notion is next-block pseudoentropy, Haitner, Reingold, and Vadhan [14], a refinement of pseudoentropy that enables simpler and more ecient construction of pseudorandom generators. The second is inaccessible entropy, Haitner, Reingold, Vadhan, andWee [11], which relates to unforgeability and is used to construct simpler and more efficient universal one-way hash functions and statistically hiding commitments.
%B Tutorials on the Foundations of Cryptography %I Springer, Yehuda Lindell, ed. %P 159-217 %G eng %U https://link.springer.com/chapter/10.1007/978-3-319-57048-8_4 %0 Book Section %B Tutorials on the Foundations of Cryptography %D 2017 %T The Complexity of Differential Privacy %A Salil Vadhan %XVersion History:
August 2016: Manuscript v1 (see files attached)
March 2017: Manuscript v2 (see files attached); Errata
April 2017: Published Version (in Tutorials on the Foundations of Cryptography; see Publisher's Version link and also SPRINGER 2017.PDF, below)
Differential privacy is a theoretical framework for ensuring the privacy of individual-level data when performing statistical analysis of privacy-sensitive datasets. This tutorial provides an introduction to and overview of differential privacy, with the goal of conveying its deep connections to a variety of other topics in computational complexity, cryptography, and theoretical computer science at large. This tutorial is written in celebration of Oded Goldreich’s 60th birthday, starting from notes taken during a minicourse given by the author and Kunal Talwar at the 26th McGill Invitational Workshop on Computational Complexity [1].
%B Tutorials on the Foundations of Cryptography %I Springer, Yehuda Lindell, ed. %P 347-450 %G eng %U https://link.springer.com/chapter/10.1007/978-3-319-57048-8_7 %0 Journal Article %J Theory of Computing – Special Issue on APPROX-RANDOM 2014 %D 2017 %T Pseudorandomness and Fourier growth bounds for width 3 branching programs %A Thomas Steinke %A Salil Vadhan %A Andrew Wan %X
Version History: a conference version of this paper appeared in the Proceedings of the 18th International Workshop on Randomization and Computation (RANDOM'14). Full version posted as ECCC TR14-076 and arXiv:1405.7028 [cs.CC].
We present an explicit pseudorandom generator for oblivious, read-once, width-3 branching programs, which can read their input bits in any order. The generator has seed length \(Õ(\log^3 n)\).The previously best known seed length for this model is \(n^{1/2+o(1)}\) due to Impagliazzo, Meka, and Zuckerman (FOCS ’12). Our work generalizes a recent result of Reingold, Steinke, and Vadhan (RANDOM ’13) for permutation branching programs. The main technical novelty underlying our generator is a new bound on the Fourier growth of width-3, oblivious, read-once branching programs. Specifically, we show that for any \(f : \{0, 1\}^n → \{0, 1\}\) computed by such a branching program, and \(k ∈ [n]\),
\(\displaystyle\sum_{s⊆[n]:|s|=k} \big| \hat{f}[s] \big | ≤n^2 ·(O(\log n))^k\),
where \(\hat{f}[s] = \mathbb{E}_U [f[U] \cdot (-1)^{s \cdot U}]\) is the standard Fourier transform over \(\mathbb{Z}^n_2\). The base \(O(\log n)\) of the Fourier growth is tight up to a factor of \(\log \log n\).
%B Theory of Computing – Special Issue on APPROX-RANDOM 2014 %I Leibniz International Proceedings in Informatics (LIPIcs) %V 13 %P 1-50 %G eng %U https://theoryofcomputing.org/articles/v013a012/ %N 12 %0 Journal Article %J Harvard Journal of Law & Technology %D 2017 %T Bridging the gap between computer science and legal approaches to privacy %A Kobbi Nissim %A Aaron Bembenek %A Alexandra Wood %A Mark Bun %A Marco Gaboardi %A Urs Gasser %A David O'Brien %A Thomas Steinke %A Salil Vadhan %XVersion History: Workshopped at PLSC (Privacy Law Scholars Conference) ‘16.
The analysis and release of statistical data about individuals and groups of individuals carries inherent privacy risks, and these risks have been conceptualized in different ways within the fields of law and computer science. For instance, many information privacy laws adopt notions of privacy risk that are sector- or context-specific, such as in the case of laws that protect from disclosure certain types of information contained within health, educational, or financial records. In addition, many privacy laws refer to specific techniques, such as deidentification, that are designed to address a subset of possible attacks on privacy. In doing so, many legal standards for privacy protection rely on individual organizations to make case-by-case determinations regarding concepts such as the identifiability of the types of information they hold. These regulatory approaches are intended to be flexible, allowing organizations to (1) implement a variety of specific privacy measures that are appropriate given their varying institutional policies and needs, (2) adapt to evolving best practices, and (3) address a range of privacy-related harms. However, in the absence of clear thresholds and detailed guidance on making case-specific determinations, flexibility in the interpretation and application of such standards also creates uncertainty for practitioners and often results in ad hoc, heuristic processes. This uncertainty may pose a barrier to the adoption of new technologies that depend on unambiguous privacy requirements. It can also lead organizations to implement measures that fall short of protecting against the full range of data privacy risks.
%B Harvard Journal of Law & Technology %V 31 %G eng %U https://jolt.law.harvard.edu/volumes/volume-31 %N 2 %0 Conference Proceedings %B 30th Conference on Learning Theory (COLT `17) %D 2017 %T On learning vs. refutation %A Salil P. Vadhan. %X Building on the work of Daniely et al. (STOC 2014, COLT 2016), we study the connection between computationally efficient PAC learning and refutation of constraint satisfaction problems. Specifically, we prove that for every concept class \(\mathcal{P }\) , PAC-learning \(\mathcal{P}\) is polynomially equivalent to “random-right-hand-side-refuting” (“RRHS-refuting”) a dual class \(\mathcal{P}^∗ \), where RRHS-refutation of a class \(Q\) refers to refuting systems of equations where the constraints are (worst-case) functions from the class \( Q\) but the right-hand-sides of the equations are uniform and independent random bits. The reduction from refutation to PAC learning can be viewed as an abstraction of (part of) the work of Daniely, Linial, and Shalev-Schwartz (STOC 2014). The converse, however, is new, and is based on a combination of techniques from pseudorandomness (Yao ‘82) with boosting (Schapire ‘90). In addition, we show that PAC-learning the class of \(DNF\) formulas is polynomially equivalent to PAC-learning its dual class \(DNF ^∗\) , and thus PAC-learning \(DNF\) is equivalent to RRHS-refutation of \(DNF\) , suggesting an avenue to obtain stronger lower bounds for PAC-learning \(DNF\) than the quasipolynomial lower bound that was obtained by Daniely and Shalev-Schwartz (COLT 2016) assuming the hardness of refuting \(k\)-SAT. %B 30th Conference on Learning Theory (COLT `17) %V 65 %P 1835-1848 %G eng %U http://proceedings.mlr.press/v65/vadhan17a.html %0 Conference Proceedings %B 58th Annual IEEE Symposium on Foundations of Computer Science (FOCS `17) %D 2017 %T Derandomization beyond connectivity: Undirected Laplacian systems in nearly logarithmic space. %A Jack Murtagh %A Omer Reingold %A Aaron Sidford %A Salil Vadhan %XVersion History:
We initiate the study of computational entropy in the quantum setting. We investigate to what extent the classical notions of computational entropy generalize to the quantum setting, and whether quantum analogues of classical theorems hold. Our main results are as follows. (1) The classical Leakage Chain Rule for pseudoentropy can be extended to the case that the leakage information is quantum (while the source remains classical). Specifically, if the source has pseudoentropy at least \(k\), then it has pseudoentropy at least \(k−ℓ \) conditioned on an \(ℓ \)-qubit leakage. (2) As an application of the Leakage Chain Rule, we construct the first quantum leakage-resilient stream-cipher in the bounded-quantum-storage model, assuming the existence of a quantum-secure pseudorandom generator. (3) We show that the general form of the classical Dense Model Theorem (interpreted as the equivalence between two definitions of pseudo-relative-min-entropy) does not extend to quantum states. Along the way, we develop quantum analogues of some classical techniques (e.g. the Leakage Simulation Lemma, which is proven by a Non-uniform Min-Max Theorem or Boosting). On the other hand, we also identify some classical techniques (e.g. Gap Amplification) that do not work in the quantum setting. Moreover, we introduce a variety of notions that combine quantum information and quantum complexity, and this raises several directions for future work.
%B Poster presention at QIP 2017 and oral presentation at QCrypt 2017 %G eng %U https://arxiv.org/abs/1704.07309 %0 Journal Article %J ACM Transactions on Economics and Computation %D 2016 %T Truthful mechanisms for agents that value privacy %A Yiling Chen %A Stephen Chong %A Ian A. Kash %A Tal Moran %A Salil P. Vadhan %XVersion History: Special issue on EC ‘13. Preliminary version at arXiv:1111.5472 [cs.GT] (Nov. 2011).
Recent work has constructed economic mechanisms that are both truthful and differentially private. In these mechanisms, privacy is treated separately from truthfulness; it is not incorporated in players’ utility functions (and doing so has been shown to lead to nontruthfulness in some cases). In this work, we propose a new, general way of modeling privacy in players’ utility functions. Specifically, we only assume that if an outcome \({o}\) has the property that any report of player \({i}\) would have led to \({o}\) with approximately the same probability, then \({o}\) has a small privacy cost to player \({i}\). We give three mechanisms that are truthful with respect to our modeling of privacy: for an election between two candidates, for a discrete version of the facility location problem, and for a general social choice problem with discrete utilities (via a VCG-like mechanism). As the number \({n}\) of players increases, the social welfare achieved by our mechanisms approaches optimal (as a fraction of \({n}\)).
%B ACM Transactions on Economics and Computation %V 4 %G eng %U https://dl.acm.org/doi/abs/10.1145/2892555 %N 3 %0 Journal Article %J Berkeley Technology Law Journal %D 2016 %T Towards a modern approach to a privacy-aware government data releases %A Micah Altman %A Alexandra Wood %A David R. O'Brien %A Salil Vadhan %A Urs Gasser %X Governments are under increasing pressure to publicly release collected data in order to promote transparency, accountability, and innovation. Because much of the data they release pertains to individuals, agencies rely on various standards and interventions to protect privacy interests while supporting a range of beneficial uses of the data. However, there are growing concerns among privacy scholars, policymakers, and the public that these approaches are incomplete, inconsistent, and difficult to navigate. To identify gaps in current practice, this Article reviews data released in response to freedom of information and Privacy Act requests, traditional public and vital records, official statistics, and e-government and open government initiatives. It finds that agencies lack formal guidance for implementing privacy interventions in specific cases. Most agencies address privacy by withholding or redacting records that contain directly or indirectly identifying information based on an ad hoc balancing of interests, and different government actors sometimes treat similar privacy risks vastly differently. These observations demonstrate the need for a more systematic approach to privacy analysis and also suggest a new way forward. In response to these concerns, this Article proposes a framework for a modern privacy analysis informed by recent advances in data privacy from disciplines such as computer science, statistics, and law. Modeled on an information security approach, this framework characterizes and distinguishes between privacy controls, threats, vulnerabilities, and utility. When developing a data release mechanism, policymakers should specify the desired data uses and expected benefits, examine each stage of the data lifecycle to identify privacy threats and vulnerabilities, and select controls for each lifecycle stage that are consistent with the uses, threats, and vulnerabilities at that stage. This Article sketches the contours of this analytical framework, populates selected portions of its contents, and illustrates how it can inform the selection of privacy controls by discussing its application to two real-world examples of government data releases. %B Berkeley Technology Law Journal %V 30 %P 1967-2072 %G eng %U https://lawcat.berkeley.edu/record/1127405 %N 3 %0 Conference Paper %B Proceedings of the 35th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems (PODS ‘16) %D 2016 %T Locating a small cluster privately %A Kobbi Nissim %A Uri Stemmer %A Salil Vadhan %XVersion History: Full version posted as arXiv:1604.05590 [cs.DS].
We present a new algorithm for locating a small cluster of points with differential privacy [Dwork, McSherry, Nissim, and Smith, 2006]. Our algorithm has implications to private data exploration, clustering, and removal of outliers. Furthermore, we use it to significantly relax the requirements of the sample and aggregate technique [Nissim, Raskhodnikova, and Smith, 2007], which allows compiling of “off the shelf” (non-private) analyses into analyses that preserve differential privacy.
Version History: Preliminary version posted as arXiv:1602.03090.
Hypothesis testing is a useful statistical tool in determining whether a given model should be rejected based on a sample from the population. Sample data may contain sensitive information about individuals, such as medical information. Thus it is important to design statistical tests that guarantee the privacy of subjects in the data. In this work, we study hypothesis testing subject to differential privacy, specifically chi-squared tests for goodness of fit for multinomial data and independence between two categorical variables.
We propose new tests for goodness of fit and independence testing that like the classical versions can be used to determine whether a given model should be rejected or not, and that additionally can ensure differential privacy. We give both Monte Carlo based hypothesis tests as well as hypothesis tests that more closely follow the classical chi-squared goodness of fit test and the Pearson chi-squared test for independence. Crucially, our tests account for the distribution of the noise that is injected to ensure privacy in determining significance.
We show that these tests can be used to achieve desired significance levels, in sharp contrast to direct applications of classical tests to differentially private contingency tables which can result in wildly varying significance levels. Moreover, we study the statistical power of these tests. We empirically show that to achieve the same level of power as the classical non-private tests our new tests need only a relatively modest increase in sample size.
%B M. Balcan and K. Weinberger, editors, Proceedings of the 33rd International Conference on Machine Learning (ICML ‘16) %I 2111-2120 %G eng %U http://proceedings.mlr.press/v48/rogers16.html %0 Conference Paper %B Poster presentation at the 2nd Workshop on the Theory and Practice of Differential Privacy (TPDP ‘16) %D 2016 %T PSI (Ψ): a private data-sharing interface %A Marco Gaboardi %A James Honaker %A Gary King %A Jack Murtagh %A Kobbi Nissim %A Jonathan Ullman %A Salil Vadhan %XVersion History: Paper posted as arXiv:1609.04340 [cs.CR].
We provide an overview of the design of PSI (“a Private data Sharing Interface”), a system we are developing to enable researchers in the social sciences and other fields to share and explore privacy-sensitive datasets with the strong privacy protections of differential privacy.
%B Poster presentation at the 2nd Workshop on the Theory and Practice of Differential Privacy (TPDP ‘16) %G eng %U https://arxiv.org/abs/1609.04340 %0 Conference Paper %B Advances in Neural Information Processing Systems 29 (NIPS `16) %D 2016 %T Privacy odometers and filters: Pay-as-you-go composition %A Ryan Rogers %A Aaron Roth %A Jonathan Ullman %A Salil Vadhan %XVersion History: Full version posted as https://arxiv.org/abs/1605.08294.
In this paper we initiate the study of adaptive composition in differential privacy when the length of the composition, and the privacy parameters themselves can be chosen adaptively, as a function of the outcome of previously run analyses. This case is much more delicate than the setting covered by existing composition theorems, in which the algorithms themselves can be chosen adaptively, but the privacy parameters must be fixed up front. Indeed, it isn’t even clear how to define differential privacy in the adaptive parameter setting. We proceed by defining two objects which cover the two main use cases of composition theorems. A privacy filter is a stopping time rule that allows an analyst to halt a computation before his pre-specified privacy budget is exceeded. A privacy odometer allows the analyst to track realized privacy loss as he goes, without needing to pre-specify a privacy budget. We show that unlike the case in which privacy parameters are fixed, in the adaptive parameter setting, these two use cases are distinct. We show that there exist privacy filters with bounds comparable (up to constants) with existing pri- vacy composition theorems. We also give a privacy odometer that nearly matches non-adaptive private composition theorems, but is sometimes worse by a small asymptotic factor. Moreover, we show that this is inherent, and that any valid privacy odometer in the adaptive parameter setting must lose this factor, which shows a formal separation between the filter and odometer use-cases.
%B Advances in Neural Information Processing Systems 29 (NIPS `16) %I 1921-1929 %G eng %U https://dl.acm.org/citation.cfm?id=3157312 %0 Conference Paper %B Martin Hirt and Adam D. Smith, editors, Proceedings of the 14th IACR Theory of Cryptography Conference (TCC `16-B) %D 2016 %T Separating computational and statistical differential privacy in the client-server model %A Mark Bun %A Yi-Hsiu Chen %A Salil Vadhan %XVersion History: Full version posted on Cryptology ePrint Archive, Report 2016/820.
Differential privacy is a mathematical definition of privacy for statistical data analysis. It guarantees that any (possibly adversarial) data analyst is unable to learn too much information that is specific to an individual. Mironov et al. (CRYPTO 2009) proposed several computa- tional relaxations of differential privacy (CDP), which relax this guarantee to hold only against computationally bounded adversaries. Their work and subsequent work showed that CDP can yield substantial accuracy improvements in various multiparty privacy problems. However, these works left open whether such improvements are possible in the traditional client-server model of data analysis. In fact, Groce, Katz and Yerukhimovich (TCC 2011) showed that, in this setting, it is impossible to take advantage of CDP for many natural statistical tasks.
Our main result shows that, assuming the existence of sub-exponentially secure one-way functions and 2-message witness indistinguishable proofs (zaps) for NP, that there is in fact a computational task in the client-server model that can be efficiently performed with CDP, but is infeasible to perform with information-theoretic differential privacy.
%B Martin Hirt and Adam D. Smith, editors, Proceedings of the 14th IACR Theory of Cryptography Conference (TCC `16-B) %I Lecture Notes in Computer Science. Springer Verlag, 31 October-3 November %G eng %U https://link.springer.com/chapter/10.1007/978-3-662-53641-4_23 %0 Journal Article %J ACM Transactions on Economics and Computation %D 2016 %T Truthful mechanisms for agents that value privacy. %A Yiling Chen %A Stephen Chong %A Ian A. Kash %A Tal Moran %A Salil P. Vadhan %X Recent work has constructed economic mechanisms that are both truthful and differentially private. In these mechanisms, privacy is treated separately from truthfulness; it is not incorporated in players’ utility functions (and doing so has been shown to lead to nontruthfulness in some cases). In this work, we propose a new, general way of modeling privacy in players’ utility functions. Specifically, we only assume that if an outcome o has the property that any report of player i would have led to o with approximately the same probability, then o has a small privacy cost to player i. We give three mechanisms that are truthful with respect to our modeling of privacy: for an election between two candidates, for a discrete version of the facility location problem, and for a general social choice problem with discrete utilities (via a VCG-like mechanism). As the number n of players increases, the social welfare achieved by our mechanisms approaches optimal (as a fraction of n). Preliminary version on arXiv (2011). %B ACM Transactions on Economics and Computation %V 4 %G eng %U https://dl.acm.org/citation.cfm?id=2905047.2892555 %N 3 %0 Manuscript %D 2015 %T Integrating approaches to privacy across the research lifecycle: When is information purely public? %A David O'Brien %A Jonathan Ullman %A Micah Altman %A Urs Gasser %A Michael Bar-Sinai %A Kobbi Nissim %A Salil Vadhan %A Michael Wojcik %A Alexandra Wood %XVersion History: Available at SSRN: http://ssrn.com/abstract=2586158.
On September 24-25, 2013, the Privacy Tools for Sharing Research Data project at Harvard University held a workshop titled "Integrating Approaches to Privacy across the Research Data Lifecycle." Over forty leading experts in computer science, statistics, law, policy, and social science research convened to discuss the state of the art in data privacy research. The resulting conversations centered on the emerging tools and approaches from the participants’ various disciplines and how they should be integrated in the context of real-world use cases that involve the management of confidential research data.
Researchers are increasingly obtaining data from social networking websites, publicly-placed sensors, government records and other public sources. Much of this information appears public, at least to first impressions, and it is capable of being used in research for a wide variety of purposes with seemingly minimal legal restrictions. The insights about human behaviors we may gain from research that uses this data are promising. However, members of the research community are questioning the ethics of these practices, and at the heart of the matter are some difficult questions about the boundaries between public and private information. This workshop report, the second in a series, identifies selected questions and explores issues around the meaning of “public” in the context of using data about individuals for research purposes.
Version History: Full version posted as arXiv:1504.07553.
We prove new upper and lower bounds on the sample complexity of \((\varepsilon, \delta)\) differentially private algorithms for releasing approximate answers to threshold functions. A threshold function \(c_x\) over a totally ordered domain \(X\) evaluates to \(c_x(y)=1 \) if \(y \leq {x}\), and evaluates to \(0\) otherwise. We give the first nontrivial lower bound for releasing thresholds with \((\varepsilon, \delta)\) differential privacy, showing that the task is impossible over an infinite domain \(X\), and moreover requires sample complexity \(n \geq \Omega(\log^* |X|)\), which grows with the size of the domain. Inspired by the techniques used to prove this lower bound, we give an algorithm for releasing thresholds with \(n ≤ 2^{(1+o(1)) \log^∗|X|}\) samples. This improves the previous best upper bound of \(8^{(1+o(1)) \log^∗ |X|}\)(Beimel et al., RANDOM ’13).
Our sample complexity upper and lower bounds also apply to the tasks of learning distri- butions with respect to Kolmogorov distance and of properly PAC learning thresholds with differential privacy. The lower bound gives the first separation between the sample complexity of properly learning a concept class with \((\varepsilon, \delta)\) differential privacy and learning without privacy. For properly learning thresholds in \(\ell\) dimensions, this lower bound extends to \(n ≥ Ω(\ell·\log^∗ |X|)\).
To obtain our results, we give reductions in both directions from releasing and properly learning thresholds and the simpler interior point problem. Given a database \(D\) of elements from \(X\), the interior point problem asks for an element between the smallest and largest elements in \(D\). We introduce new recursive constructions for bounding the sample complexity of the interior point problem, as well as further reductions and techniques for proving impossibility results for other basic problems in differential privacy.
%B Proceedings of the 56th Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘15) %I IEEE %G eng %U https://ieeexplore.ieee.org/document/7354419 %0 Manuscript %D 2015 %T Pseudorandomness for read-once, constant-depth circuits %A Sitan Chen %A Thomas Steinke %A Salil P. Vadhan %XFor Boolean functions computed by read-once, depth-D circuits with unbounded fan-in over the de Morgan basis, we present an explicit pseudorandom generator with seed length \(\tilde{O}(\log^{D+1} n)\). The previous best seed length known for this model was \(\tilde{O}(\log^{D+4} n)\), obtained by Trevisan and Xue (CCC ‘13) for all of AC0 (not just read-once). Our work makes use of Fourier analytic techniques for pseudorandomness introduced by Reingold, Steinke, and Vadhan (RANDOM ‘13) to show that the generator of Gopalan et al. (FOCS ‘12) fools read-once AC0. To this end, we prove a new Fourier growth bound for read-once circuits, namely that for every \(F : \{0,1\}^n\rightarrow \{0,1\}\) computed by a read-once, depth-\(D\) circuit,
\(\left|\hat{F}[s]\right| \leq O\left(\log^{D-1} n\right)^k,\)
where \(\hat{F}\) denotes the Fourier transform of \(F\) over \(\mathbb{Z}_2^n\).
%B CoRR %G eng %U https://arxiv.org/abs/1504.04675 %N 1504.04675 %0 Conference Paper %B Proceedings of the 56th Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘15) %D 2015 %T Robust traceability from trace amounts %A Cynthia Dwork %A Adam Smith %A Thomas Steinke %A Jonathan Ullman %A Salil Vadhan %XThe privacy risks inherent in the release of a large number of summary statistics were illustrated by Homer et al. (PLoS Genetics, 2008), who considered the case of 1-way marginals of SNP allele frequencies obtained in a genome-wide association study: Given a large number of minor allele frequencies from a case group of individuals diagnosed with a particular disease, together with the genomic data of a single target individual and statistics from a sizable reference dataset independently drawn from the same population, an attacker can determine with high confidence whether or not the target is in the case group.
In this work we describe and analyze a simple attack that succeeds even if the summary statistics are significantly distorted, whether due to measurement error or noise intentionally introduced to protect privacy. Our attack only requires that the vector of distorted summary statistics is close to the vector of true marginals in \(\ell_1 \)norm. Moreover, the reference pool required by previous attacks can be replaced by a single sample drawn from the underlying population.
The new attack, which is not specific to genomics and which handles Gaussian as well as Bernouilli data, significantly generalizes recent lower bounds on the noise needed to ensure differential privacy (Bun, Ullman, and Vadhan, STOC 2014; Steinke and Ullman, 2015), obviating the need for the attacker to control the exact distribution of the data.
%B Proceedings of the 56th Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘15) %I IEEE %P 650-669 %G eng %U https://ieeexplore.ieee.org/document/7354420 %0 Conference Paper %B In Moni Naor, editor, Innovations in Theoretical Computer Science (ITCS ‘14) %D 2014 %T Locally testable codes and Cayley graphs %A Parikshit Gopalan %A Salil Vadhan %A Yuan Zhou %XVersion History: Full version posted as https://arxiv.org/pdf/1308.5158.pdf.
We give two new characterizations of (\(\mathbb{F}_2\)-linear) locally testable error-correcting codes in terms of Cayley graphs over \(\mathbb{F}^h_2\) :
A locally testable code is equivalent to a Cayley graph over \(\mathbb{F}^h_2\) whose set of generators is significantly larger than \(h\) and has no short linear dependencies, but yields a shortest-path metric that embeds into \(\ell_1\) with constant distortion. This extends and gives a converse to a result of Khot and Naor (2006), which showed that codes with large dual distance imply Cayley graphs that have no low-distortion embeddings into \(\ell_1\).
A locally testable code is equivalent to a Cayley graph over \(\mathbb{F}^h_2\) that has significantly more than \(h\) eigenvalues near 1, which have no short linear dependencies among them and which “explain” all of the large eigenvalues. This extends and gives a converse to a recent construction of Barak et al. (2012), which showed that locally testable codes imply Cayley graphs that are small-set expanders but have many large eigenvalues.
Version History: Full version posted as arXiv:1401.4092 [cs.GT].
We prove new positive and negative results concerning the existence of truthful and individually rational mechanisms for purchasing private data from individuals with unbounded and sensitive privacy preferences. We strengthen the impos- sibility results of Ghosh and Roth (EC 2011) by extending it to a much wider class of privacy valuations. In particular, these include privacy valuations that are based on \((\varepsilon, \delta)\)- differentially private mechanisms for non-zero \(\delta\), ones where the privacy costs are measured in a per-database manner (rather than taking the worst case), and ones that do not depend on the payments made to players (which might not be observable to an adversary).
To bypass this impossibility result, we study a natural special setting where individuals have monotonic privacy valuations, which captures common contexts where certain values for private data are expected to lead to higher valuations for privacy (e.g. having a particular disease). We give new mechanisms that are individually rational for all players with monotonic privacy valuations, truthful for all players whose privacy valuations are not too large, and accu- rate if there are not too many players with too-large privacy valuations. We also prove matching lower bounds showing that in some respects our mechanism cannot be improved significantly.
%B Moni Naor, editor, Innovations in Theoretical Computer Science (ITCS ‘14) %I ACM %P 411-422 %G eng %U https://dl.acm.org/citation.cfm?id=2554835 %0 Manuscript %D 2014 %T Integrating approaches to privacy across the research lifecycle: Long-term longitudinal studies %A Alexandra Wood %A David O'Brien %A Micah Altman %A Alan Karr %A Urs Gasser %A Michael Bar-Sinai %A Kobbi Nissim %A Jonathan Ullman %A Salil Vadhan %A Michael Wojcik %XVersion History: Available at SSRN: http://ssrn.com/abstract=2469848.
On September 24-25, 2013, the Privacy Tools for Sharing Research Data project at Harvard University held a workshop titled "Integrating Approaches to Privacy across the Research Data Lifecycle." Over forty leading experts in computer science, statistics, law, policy, and social science research convened to discuss the state of the art in data privacy research. The resulting conversations centered on the emerging tools and approaches from the participants’ various disciplines and how they should be integrated in the context of real-world use cases that involve the management of confidential research data.
This workshop report, the first in a series, provides an overview of the long-term longitudinal study use case. Long-term longitudinal studies collect, at multiple points over a long period of time, highly-specific and often sensitive data describing the health, socioeconomic, or behavioral characteristics of human subjects. The value of such studies lies in part in their ability to link a set of behaviors and changes to each individual, but these factors tend to make the combination of observable characteristics associated with each subject unique and potentially identifiable.
Using the research information lifecycle as a framework, this report discusses the defining features of long-term longitudinal studies and the associated challenges for researchers tasked with collecting and analyzing such data while protecting the privacy of human subjects. It also describes the disclosure risks and common legal and technical approaches currently used to manage confidentiality in longitudinal data. Finally, it identifies urgent problems and areas for future research to advance the integration of various methods for preserving confidentiality in research data.
%B Berkman Center Research Publication No. 2014-12 %G eng %U https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2469848 %N July %0 Journal Article %J Theory of Computing %D 2013 %T Why simple hash functions work: Exploiting the entropy in a data stream %A Kai-Min Chung %A Michael Mitzenmacher %A Salil P. Vadhan %XVersion History: Merge of conference papers from SODA ‘08 (with the same title) and RANDOM ‘08 (entitled “Tight Bounds for Hashing Block Sources”).
Hashing is fundamental to many algorithms and data structures widely used in practice. For the theoretical analysis of hashing, there have been two main approaches. First, one can assume that the hash function is truly random, mapping each data item independently and uniformly to the range. This idealized model is unrealistic because a truly random hash function requires an exponential number of bits (in the length of a data item) to describe. Alternatively, one can provide rigorous bounds on performance when explicit families of hash functions are used, such as 2-universal or \(O\)(1)-wise independent families. For such families, performance guarantees are often noticeably weaker than for ideal hashing.
In practice, however, it is commonly observed that simple hash functions, including 2-universal hash functions, perform as predicted by the idealized analysis for truly random hash functions. In this paper, we try to explain this phenomenon. We demonstrate that the strong performance of universal hash functions in practice can arise naturally from a combination of the randomness of the hash function and the data. Specifically, following the large body of literature on random sources and randomness extraction, we model the data as coming from a “block source,” whereby each new data item has some “entropy” given the previous ones. As long as the Rényi entropy per data item is sufficiently large, it turns out that the performance when choosing a hash function from a 2-universal family is essentially the same as for a truly random hash function. We describe results for several sample applications, including linear probing, chained hashing, balanced allocations, and Bloom filters.
Towards developing our results, we prove tight bounds for hashing block sources, determining the entropy required per block for the distribution of hashed values to be close to uniformly distributed.
%B Theory of Computing %V 9 %P 897-945 %G eng %U https://theoryofcomputing.org/articles/v009a030/ %0 Journal Article %J SIAM Journal on Computing %D 2013 %T Efficiency improvements in constructing pseudorandom generators from one-way functions %A Iftach Haitner %A Omer Reingold %A Salil Vadhan %X
Version History: Special Issue on STOC ‘10.
We give a new construction of pseudorandom generators from any one-way function. The construction achieves better parameters and is simpler than that given in the seminal work of Håstad, Impagliazzo, Levin, and Luby [SICOMP ’99]. The key to our construction is a new notion of next-block pseudoentropy, which is inspired by the notion of “in-accessible entropy” recently introduced in [Haitner, Reingold, Vadhan, and Wee, STOC ’09]. An additional advan- tage over previous constructions is that our pseudorandom generators are parallelizable and invoke the one-way function in a non-adaptive manner. Using [Applebaum, Ishai, and Kushilevitz, SICOMP ’06], this implies the existence of pseudorandom generators in NC\(^0\) based on the existence of one-way functions in NC\(^1\).
%B SIAM Journal on Computing %V 42 %P 1405-1430 %G eng %U https://epubs.siam.org/doi/abs/10.1137/100814421 %N 3 %0 Journal Article %J Random Structures & Algorithms %D 2013 %T On extractors and exposure-resilient functions for sublogarithmic entropy %A Yakir Reshef %A Salil Vadhan %XVersion History: Preliminary version posted as arXiv:1003.4029 (Dec. 2010).
We study resilient functions and exposure‐resilient functions in the low‐entropy regime. A resilient function (a.k.a. deterministic extractor for oblivious bit‐fixing sources) maps any distribution on n‐bit strings in which k bits are uniformly random and the rest are fixed into an output distribution that is close to uniform. With exposure‐resilient functions, all the input bits are random, but we ask that the output be close to uniform conditioned on any subset of n – k input bits. In this paper, we focus on the case that k is sublogarithmic in n.
We simplify and improve an explicit construction of resilient functions for k sublogarithmic in n due to Kamp and Zuckerman (SICOMP 2006), achieving error exponentially small in krather than polynomially small in k. Our main result is that when k is sublogarithmic in n, the short output length of this construction (\(O(\log k)\) output bits) is optimal for extractors computable by a large class of space‐bounded streaming algorithms.
Next, we show that a random function is a resilient function with high probability if and only if k is superlogarithmic in n, suggesting that our main result may apply more generally. In contrast, we show that a random function is a static (resp. adaptive) exposure‐resilient function with high probability even if k is as small as a constant (resp. log log n). No explicit exposure‐resilient functions achieving these parameters are known.
%B Random Structures & Algorithms %V 42 %P 386-401 %G eng %U https://onlinelibrary.wiley.com/doi/abs/10.1002/rsa.20424 %N 3 %0 Conference Paper %B Innovations in Theoretical Computer Science (ITCS ‘13) %D 2013 %T Publicly verifiable proofs of sequential work %A Mohammad Mahmoody %A Tal Moran %A Salil Vadhan %X
Version History: Preliminary version posted as Cryptology ePrint Archive Report 2011/553, under title “Non-Interactive Time-Stamping and Proofs of Work in the Random Oracle Model”.
We construct a publicly verifiable protocol for proving computational work based on collision- resistant hash functions and a new plausible complexity assumption regarding the existence of “inherently sequential” hash functions. Our protocol is based on a novel construction of time-lock puzzles. Given a sampled “puzzle” \(\mathcal{P} \overset{$}\gets \mathbf{D}_n\), where \(n\) is the security parameter and \(\mathbf{D}_n\) is the distribution of the puzzles, a corresponding “solution” can be generated using \(N\) evaluations of the sequential hash function, where \(N > n\) is another parameter, while any feasible adversarial strategy for generating valid solutions must take at least as much time as \(\Omega(N)\) sequential evaluations of the hash function after receiving \(\mathcal{P}\). Thus, valid solutions constitute a “proof” that \(\Omega(N)\) parallel time elapsed since \(\mathcal{P}\) was received. Solutions can be publicly and efficiently verified in time \(\mathrm{poly}(n) \cdot \mathrm{polylog}(N)\). Applications of these “time-lock puzzles” include noninteractive timestamping of documents (when the distribution over the possible documents corresponds to the puzzle distribution \(\mathbf{D}_n\)) and universally verifiable CPU benchmarks.
Our construction is secure in the standard model under complexity assumptions (collision- resistant hash functions and inherently sequential hash functions), and makes black-box use of the underlying primitives. Consequently, the corresponding construction in the random oracle model is secure unconditionally. Moreover, as it is a public-coin protocol, it can be made non- interactive in the random oracle model using the Fiat-Shamir Heuristic.
Our construction makes a novel use of “depth-robust” directed acyclic graphs—ones whose depth remains large even after removing a constant fraction of vertices—which were previously studied for the purpose of complexity lower bounds. The construction bypasses a recent negative result of Mahmoody, Moran, and Vadhan (CRYPTO ‘11) for time-lock puzzles in the random oracle model, which showed that it is impossible to have time-lock puzzles like ours in the random oracle model if the puzzle generator also computes a solution together with the puzzle.
%B Innovations in Theoretical Computer Science (ITCS ‘13) %I ACM %P 373-388 %G eng %U https://dl.acm.org/citation.cfm?id=2422479 %0 Conference Paper %B Proceedings of the 45th Annual ACM Symposium on Theory of Computing (STOC ‘13) %D 2013 %T Interactive proofs of proximity: delegating computation in sublinear time %A Guy N. Rothblum %A Salil Vadhan %A Avi Wigderson %XWe study interactive proofs with sublinear-time verifiers. These proof systems can be used to ensure approximate correctness for the results of computations delegated to an untrusted server. Following the literature on property testing, we seek proof systems where with high probability the verifier accepts every input in the language, and rejects every input that is far from the language. The verifier’s query complexity (and computation complexity), as well as the communication, should all be sublinear. We call such a proof system an Interactive Proof of Proximity (IPP).
On the positive side, our main result is that all languages in \(\mathcal{NC}\) have Interactive Proofs of Proximity with roughly \(\sqrt{n}\) query and communication and complexities, and \(\mathrm{polylog} (n)\) communication rounds.
This is achieved by identifying a natural language, membership in an affine subspace (for a structured class of subspaces), that is complete for constructing interactive proofs of proximity, and providing efficient protocols for it. In building an IPP for this complete language, we show a tradeoff between the query and communication complexity and the number of rounds. For example, we give a 2-round protocol with roughly \(n^{3/4}\) queries and communication.
On the negative side, we show that there exist natural languages in \(\mathcal{NC}^1\), for which the sum of queries and communication in any constant-round interactive proof of proximity must be polynomially related to n. In particular, for any 2-round protocol, the sum of queries and communication must be at least \(\tilde{\Omega}(\sqrt{n})\).
Finally, we construct much better IPPs for specific functions, such as bipartiteness on random or well-mixing graphs, and the majority function. The query complexities of these protocols are provably better (by exponential or polynomial factors) than what is possible in the standard property testing model, i.e. without a prover.
We present a new, more constructive proof of von Neumann’s Min-Max Theorem for two-player zero-sum game — specifically, an algorithm that builds a near-optimal mixed strategy for the second player from several best-responses of the second player to mixed strategies of the first player. The algorithm extends previous work of Freund and Schapire (Games and Economic Behavior ’99) with the advantage that the algorithm runs in poly\((n)\) time even when a pure strategy for the first player is a distribution chosen from a set of distributions over \(\{0,1\}^n\). This extension enables a number of additional applications in cryptography and complexity theory, often yielding uniform security versions of results that were previously only proved for nonuniform security (due to use of the non-constructive Min-Max Theorem).
We describe several applications, including a more modular and improved uniform version of Impagliazzo’s Hardcore Theorem (FOCS ’95), showing impossibility of constructing succinct non-interactive arguments (SNARGs) via black-box reductions under uniform hardness assumptions (using techniques from Gentry and Wichs (STOC ’11) for the nonuniform setting), and efficiently simulating high entropy distributions within any sufficiently nice convex set (extending a result of Trevisan, Tulsiani and Vadhan (CCC ’09)).
%B Ran Canetti and Juan Garay, editors, Advances in Cryptology—CRYPTO ‘13, Lecture Notes on Computer Science %I Springer Verlag, Lecture Notes in Computer Science %V 8042 %P 93-110 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-40041-4_6 %0 Conference Paper %B Sofya Raskhodnikova and José Rolim, editors, Proceedings of the 17th International Workshop on Randomization and Computation (RANDOM ‘13), Lecture Notes in Computer Science %D 2013 %T Pseudorandomness for regular branching programs via Fourier analysis %A Omer Reingold %A Thomas Steinke %A Salil Vadhan %XVersion History: Full version posted as ECCC TR13-086 and arXiv:1306.3004 [cs.CC].
We present an explicit pseudorandom generator for oblivious, read-once, permutation branching programs of constant width that can read their input bits in any order. The seed length is \(O(\log^2n)\), where \(n\) is the length of the branching program. The previous best seed length known for this model was \(n^{1/2+o(1)}\), which follows as a special case of a generator due to Impagliazzo, Meka, and Zuckerman (FOCS 2012) (which gives a seed length of \(s^{1/2+o(1)}\) for arbitrary branching programs of size \(s\)). Our techniques also give seed length \(n^{1/2+o(1)}\) for general oblivious, read-once branching programs of width \(2^{n^{o(1)}}\)) , which is incomparable to the results of Impagliazzo et al.
Our pseudorandom generator is similar to the one used by Gopalan et al. (FOCS 2012) for read-once CNFs, but the analysis is quite different; ours is based on Fourier analysis of branching programs. In particular, we show that an oblivious, read-once, regular branching program of width \(w\) has Fourier mass at most \((2w^2)^k\) at level \(k\), independent of the length of the program.
%B Sofya Raskhodnikova and José Rolim, editors, Proceedings of the 17th International Workshop on Randomization and Computation (RANDOM ‘13), Lecture Notes in Computer Science %I Springer-Verlag %V 8096 %P 655-670 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-40328-6_45 %0 Journal Article %J ACM Transactions on Computation Theory %D 2012 %T The computational complexity of Nash equilibria in concisely represented games %A Grant Schoenebeck %A Salil Vadhan %XVersion History: Preliminary versions as ECCC TOR05-52 (https://eccc.weizmann.ac.il/report/2005/052/; attached as ECCC2005.pdf) and in EC '06 (https://dl.acm.org/doi/10.1145/1134707.1134737; attached as EC2006.pdf).
Games may be represented in many different ways, and different representations of games affect the complexity of problems associated with games, such as finding a Nash equilibrium. The traditional method of representing a game is to explicitly list all the payoffs, but this incurs an exponential blowup as the number of agents grows. We study two models of concisely represented games: circuit games, where the payoffs are computed by a given boolean circuit, and graph games, where each agent’s payoff is a function of only the strategies played by its neighbors in a given graph. For these two models, we study the complexity of four questions: determining if a given strategy is a Nash equilibrium, finding a Nash equilibrium, determining if there exists a pure Nash equilibrium, and determining if there exists a Nash equilibrium in which the payoffs to a player meet some given guarantees. In many cases, we obtain tight results, showing that the problems are complete for various complexity classes.
%B ACM Transactions on Computation Theory %V 4 %G eng %U https://dl.acm.org/doi/abs/10.1145/2189778.2189779 %N 2 %0 Conference Paper %B Ronald Cramer, editor, Proceedings of the 9th IACR Theory of Cryptography Conference (TCC ‘12), Lecture Notes on Computer Science %D 2012 %T Randomness condensers for efficiently samplable, seed-dependent sources %A Yevgeniy Dodis %A Thomas Ristenpart %A Salil Vadhan %XWe initiate a study of randomness condensers for sources that are efficiently samplable but may depend on the seed of the condenser. That is, we seek functions \(\mathsf{Cond} : \{0,1\}^n \times \{0,1\}^d \to \{0,1\}^m\)such that if we choose a random seed \(S \gets \{0,1\}^d\), and a source \(X = \mathcal{A}(S)\) is generated by a randomized circuit \(\mathcal{A}\) of size \(t\) such that \(X\) has min- entropy at least \(k\) given \(S\), then \(\mathsf{Cond}(X ; S)\) should have min-entropy at least some \(k'\) given \(S\). The distinction from the standard notion of randomness condensers is that the source \(X\) may be correlated with the seed \(S\) (but is restricted to be efficiently samplable). Randomness extractors of this type (corresponding to the special case where \(k' = m\)) have been implicitly studied in the past (by Trevisan and Vadhan, FOCS ‘00).
We show that:
Unlike extractors, we can have randomness condensers for samplable, seed-dependent sources whose computational complexity is smaller than the size \(t\) of the adversarial sampling algorithm \(\mathcal{A}\). Indeed, we show that sufficiently strong collision-resistant hash functions are seed-dependent condensers that produce outputs with min-entropy \(k' = m – \mathcal{O}(\log t)\), i.e. logarithmic entropy deficiency.
Randomness condensers suffice for key derivation in many cryptographic applications: when an adversary has negligible success probability (or negligible “squared advantage” [3]) for a uniformly random key, we can use instead a key generated by a condenser whose output has logarithmic entropy deficiency.
Randomness condensers for seed-dependent samplable sources that are robust to side information generated by the sampling algorithm imply soundness of the Fiat-Shamir Heuristic when applied to any constant-round, public-coin interactive proof system.
Version History: Full version posted as ECCC TR11-141.
We provide a characterization of pseudoentropy in terms of hardness of sampling: Let (\(X, B\)) be jointly distributed random variables such that \(B\) takes values in a polynomial-sized set. We show that \(B\) is computationally indistinguishable from a random variable of higher Shannon entropy given \(X\) if and only if there is no probabilistic polynomial-time \(S\) such that \((X, S(X))\) has small KL divergence from \((X, B)\). This can be viewed as an analogue of the Impagliazzo Hard- core Theorem (FOCS ‘95) for Shannon entropy (rather than min-entropy).
Using this characterization, we show that if \(f\) is a one-way function, then \((f(U_n), U_n)\) has “next-bit pseudoentropy” at least \(n + \log n\), establishing a conjecture of Haitner, Reingold, and Vadhan (STOC ‘10). Plugging this into the construction of Haitner et al., this yields a simpler construction of pseudorandom generators from one-way functions. In particular, the construction only performs hashing once, and only needs the hash functions that are randomness extractors (e.g. universal hash functions) rather than needing them to support “local list-decoding” (as in the Goldreich–Levin hardcore predicate, STOC ‘89).
With an additional idea, we also show how to improve the seed length of the pseudorandom generator to \(\tilde{O}(n^3)\), compared to \(\tilde{O}(n^4)\) in the construction of Haitner et al.
%B Proceedings of the 44th Annual ACM Symposium on Theory of Computing (STOC ‘12) %I ACM %P 817-836 %G eng %U http://doi.org/10.1145/2213977.2214051 %0 Conference Paper %B Artur Czumaj, Kurt Mehlhorn, Andrew M. Pitts, and Roger Wattenhofer, editors, Proceedings of the 39th International Colloquium on Automata, Languages, and Programming (ICALP ‘12), Lecture Notes on Computer Science %D 2012 %T Faster algorithms for privately releasing marginals %A Justin Thaler %A Jonathan Ullman %A Salil Vadhan %XVersion History: Full version posted as arXiv:1205.1758v2.
We study the problem of releasing k-way marginals of a database \(D ∈ ({0,1}^d)^n\), while preserving differential privacy. The answer to a \(k\)-way marginal query is the fraction of \(D\)’s records \(x \in \{0,1\}^d\) with a given value in each of a given set of up to \(k\) columns. Marginal queries enable a rich class of statistical analyses of a dataset, and designing efficient algorithms for privately releasing marginal queries has been identified as an important open problem in private data analysis (cf. Barak et. al., PODS ’07).
We give an algorithm that runs in time \(d^{O(\sqrt{K})}\) and releases a private summary capable of answering any \(k\)-way marginal query with at most ±.01 error on every query as long as \(n \geq d^{O(\sqrt{K})}\). To our knowledge, ours is the first algorithm capable of privately releasing marginal queries with non-trivial worst-case accuracy guarantees in time substantially smaller than the number of k-way marginal queries, which is \(d^{\Theta(k)}\) (for \(k ≪ d\)).
%B Artur Czumaj, Kurt Mehlhorn, Andrew M. Pitts, and Roger Wattenhofer, editors, Proceedings of the 39th International Colloquium on Automata, Languages, and Programming (ICALP ‘12), Lecture Notes on Computer Science %I Springer-Verlag %V 7391 %P 810-821 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-31594-7_68 %0 Conference Paper %B Ran Canetti and Rei Safavi-Naini, editors, Proceedings of the 32nd International Cryptology Conference (CRYPTO ‘12), Lecture Notes on Computer Science %D 2012 %T Differential privacy with imperfect randomness %A Yevgeniy Dodis %A Adriana López-Alt %A Ilya Mironov %A Salil Vadhan %XIn this work we revisit the question of basing cryptography on imperfect randomness. Bosley and Dodis (TCC’07) showed that if a source of randomness \(\mathcal{R}\) is “good enough” to generate a secret key capable of encrypting \(k\) bits, then one can deterministically extract nearly \(k\) almost uniform bits from \(\mathcal{R}\), suggesting that traditional privacy notions (namely, indistinguishability of encryption) requires an “extractable” source of randomness. Other, even stronger impossibility results are known for achieving privacy under specific “non-extractable” sources of randomness, such as the \(\gamma\)-Santha-Vazirani (SV) source, where each next bit has fresh entropy, but is allowed to have a small bias \(\gamma < 1\) (possibly depending on prior bits).
We ask whether similar negative results also hold for a more recent notion of privacy called differential privacy (Dwork et al., TCC’06), concentrating, in particular, on achieving differential privacy with the Santha-Vazirani source. We show that the answer is no. Specifically, we give a differentially private mechanism for approximating arbitrary “low sensitivity” functions that works even with randomness coming from a \(\gamma\)-Santha-Vazirani source, for any \(\gamma < 1\). This provides a somewhat surprising “separation” between traditional privacy and differential privacy with respect to imperfect randomness.
Interestingly, the design of our mechanism is quite different from the traditional “additive-noise” mechanisms (e.g., Laplace mechanism) successfully utilized to achieve differential privacy with perfect randomness. Indeed, we show that any (non-trivial) “SV-robust” mechanism for our problem requires a demanding property called consistent sampling, which is strictly stronger than differential privacy, and cannot be satisfied by any additive-noise mechanism.
%B Ran Canetti and Rei Safavi-Naini, editors, Proceedings of the 32nd International Cryptology Conference (CRYPTO ‘12), Lecture Notes on Computer Science %I Springer-Verlag %V 7417 %P 497-516 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-32009-5_29 %0 Conference Paper %B Proceedings of the 53rd Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘12) %D 2012 %T The privacy of the analyst and the power of the state %A Cynthia Dwork %A Moni Naor %A Salil Vadhan %X We initiate the study of privacy for the analyst in differentially private data analysis. That is, not only will we be concerned with ensuring differential privacy for the data (i.e. individuals or customers), which are the usual concern of differential privacy, but we also consider (differential) privacy for the set of queries posed by each data analyst. The goal is to achieve privacy with respect to other analysts, or users of the system. This problem arises only in the context of stateful privacy mechanisms, in which the responses to queries depend on other queries posed (a recent wave of results in the area utilized cleverly coordinated noise and state in order to allow answering privately hugely many queries). We argue that the problem is real by proving an exponential gap between the number of queries that can be answered (with non-trivial error) by stateless and stateful differentially private mechanisms. We then give a stateful algorithm for differentially private data analysis that also ensures differential privacy for the analyst and can answer exponentially many queries. %B Proceedings of the 53rd Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘12) %I IEEE %P 400-409 %G eng %U https://ieeexplore.ieee.org/document/6375318 %0 Conference Paper %B Proceedings of the 53rd Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘12) %D 2012 %T Better pseudorandom generators via milder pseudorandom restrictions %A Parikshit Gopalan %A Raghu Meka %A Omer Reingold %A Luca Tevisan %A Salil Vadhan %XVersion History: Full version posted as ECCC TR12-123 and as arXiv:1210.0049 [cs.CC].
We present an iterative approach to constructing pseudorandom generators, based on the repeated application of mild pseudorandom restrictions. We use this template to construct pseudorandom generators for combinatorial rectangles and read-once \(\mathsf{CNF}\)s and a hitting set generator for width-3 branching programs, all of which achieve near-optimal seed-length even in the low-error regime: We get seed-length \(\tilde{O}(\log(n/\epsilon))\) for error \(\epsilon\). Previously, only constructions with seed-length \(O(log^{3/2}n)\) or \(O(log^2n)\)were known for these classes with error \(\epsilon = 1/\mathrm{poly}(n)\). The (pseudo)random restrictions we use are milder than those typically used for proving circuit lower bounds in that we only set a constant fraction of the bits at a time. While such restrictions do not simplify the functions drastically, we show that they can be derandomized using small-bias spaces.
Version History: Special issue to celebrate Richard Karp's Kyoto Prize. Extended abstract in STOC '06.
We give polynomial-time, deterministic randomness extractors for sources generated in small space, where we model space \(s\) sources on\(\{0,1\}^n\) as sources generated by width \(2^s\) branching programs. Specifically, there is a constant \(η > 0\) such that for any \(ζ > n^{−η}\), our algorithm extracts \(m = (δ − ζ)n\) bits that are exponentially close to uniform (in variation distance) from space \(s\) sources with min-entropy \(δn\), where \(s = Ω(ζ^ 3n)\). Previously, nothing was known for \(δ \ll 1/2,\), even for space \(0\). Our results are obtained by a reduction to the class of total-entropy independent sources. This model generalizes both the well-studied models of independent sources and symbol-fixing sources. These sources consist of a set of \(r\) independent smaller sources over \(\{0, 1\}^\ell\), where the total min-entropy over all the smaller sources is \(k\). We give deterministic extractors for such sources when \(k\) is as small as \(\mathrm{polylog}(r)\), for small enough \(\ell\).
%B Journal of Computer and System Sciences %V 77 %P 191-220 %G eng %U https://www.sciencedirect.com/science/article/pii/S002200001000098X?via%3Dihub %N 1 %0 Conference Paper %B ACM Transactions on Algorithms %D 2011 %T S-T connectivity on digraphs with a known stationary distribution %A Kai-Min Chung %A Omer Reingold %A Salil Vadhan %X
Version history: Preliminary versions in CCC '07 and on ECCC (TR07-030).
We present a deterministic logspace algorithm for solving S-T Connectivity on directed graphs if: (i) we are given a stationary distribution of the random walk on the graph in which both of the input vertices \(s\) and \(t\) have nonnegligible probability mass and (ii) the random walk which starts at the source vertex \(s\) has polynomial mixing time. This result generalizes the recent deterministic logspace algorithm for S-T Connectivity on undirected graphs [Reingold, 2008]. It identifies knowledge of the stationary distribution as the gap between the S-T Connectivity problems we know how to solve in logspace (L) and those that capture all of randomized logspace (RL).
%B ACM Transactions on Algorithms %7 3 %I ACM %V 7 %G eng %U https://dl.acm.org/citation.cfm?id=1978785 %0 Conference Paper %B Proceedings of the Second Symposium on Innovations in Computer Science (ICS 2011) %D 2011 %T On approximating the entropy of polynomial mappings %A Zeev Dvir %A Dan Gutfreund %A Guy Rothblum %A Salil Vadhan %X
Version History: Full version posted as ECCC TR10-60.
We investigate the complexity of the following computational problem:
Polynomial Entropy Approximation (PEA): Given a low-degree polynomial mapping \(p : \mathbb{F}^n → \mathbb{F}^m\), where F is a finite field, approximate the output entropy \(H(p(U_n))\), where \(U_n\) is the uniform distribution on \(\mathbb{F}^n\) and \(H\) may be any of several entropy measures.
We show:
Approximating the Shannon entropy of degree 3 polynomials \(p : \mathbb{F}_2^n \to \mathbb{F}^m_2\) over \(\mathbb{F}_2\) to within an additive constant (or even \(n^.9\)) is complete for \(\mathbf{SZKP_L}\), the class of problems having statistical zero-knowledge proofs where the honest verifier and its simulator are computable in logarithmic space. (\(\mathbf{SZKP_L}\)contains most of the natural problems known to be in the full class \(\mathbf{SZKP}\).)
For prime fields \(\mathbb{F} \neq \mathbb{F}_2\) and homogeneous quadratic polynomials \(p : \mathbb{F}^n \to \mathbb{F}^m\), there is a probabilistic polynomial-time algorithm that distinguishes the case that \(p(U_n)\)) has entropy smaller than k from the case that \(p(U_n))\) has min-entropy (or even Renyi entropy) greater than \((2 + o(1))k\).
For degree d polynomials \(p : \mathbb{F}^n_2 \to \mathbb{F}^m_2\) , there is a polynomial-time algorithm that distinguishes the case that \(p(U_n)\) has max-entropy smaller than \(k\) (where the max-entropy of a random variable is the logarithm of its support size) from the case that \(p(U_n)\) has max-entropy at least \((1 + o(1)) \cdot k^d\) (for fixed \(d\) and large \(k\)).
A time-lock puzzle is a mechanism for sending messages “to the future”. The sender publishes a puzzle whose solution is the message to be sent, thus hiding it until enough time has elapsed for the puzzle to be solved. For time-lock puzzles to be useful, generating a puzzle should take less time than solving it. Since adversaries may have access to many more computers than honest solvers, massively parallel solvers should not be able to produce a solution much faster than serial ones.
To date, we know of only one mechanism that is believed to satisfy these properties: the one proposed by Rivest, Shamir and Wagner (1996), who originally introduced the notion of time-lock puzzles. Their puzzle is based on the serial nature of exponentiation and the hardness of factoring, and is therefore vulnerable to advances in factoring techniques (as well as to quantum attacks).
In this work, we study the possibility of constructing time-lock puzzles in the random-oracle model. Our main result is negative, ruling out time-lock puzzles that require more parallel time to solve than the total work required to generate a puzzle. In particular, this should rule out black-box constructions of such time-lock puzzles from one-way permutations and collision-resistant hash-functions. On the positive side, we construct a time-lock puzzle with a linear gap in parallel time: a new puzzle can be generated with one round of \({n}\) parallel queries to the random oracle, but \({n}\) rounds of serial queries are required to solve it (even for massively parallel adversaries).
%B P. Rogaway, editor, Advances in Cryptology—CRYPTO ‘11, Lecture Notes in Computer Science %I Springer-Verlag %V 6841 %P 39-50 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-22792-9_3 %0 Journal Article %J IEEE Transactions on Information Theory %D 2010 %T A lower bound on list size for list decoding %A Venkatesan Guruswami %A Salil Vadhan %XVersion History: Preliminary version published in RANDOM '05 (https://link.springer.com/chapter/10.1007/11538462_27) and attached as RANDOM2005.pdf.
A q-ary error-correcting code \(C ⊆ \{1,2,...,q\}^n\) is said to be list decodable to radius \(\rho\) with list size L if every Hamming ball of radius ρ contains at most L codewords of C. We prove that in order for a q-ary code to be list-decodable up to radius \((1–1/q)(1–ε)n\), we must have \(L = Ω(1/ε^2)\). Specifically, we prove that there exists a constant \(c_q >0\) and a function \(f_q\) such that for small enough \(ε > 0\), if C is list-decodable to radius\( (1–1/q)(1–ε)n \)with list size \(c_q /ε^2\), then C has at most \(f q (ε) \)codewords, independent of n. This result is asymptotically tight (treating q as a constant), since such codes with an exponential (in n) number of codewords are known for list size \(L = O(1/ε^2)\).
A result similar to ours is implicit in Blinovsky [Bli] for the binary \((q=2)\) case. Our proof works for all alphabet sizes, and is technically and conceptually simpler.
%B IEEE Transactions on Information Theory %V 56 %P 5681-5688 %G eng %U https://ieeexplore.ieee.org/document/5605366 %N 11 %0 Journal Article %J Computational Complexity %D 2010 %T Are PCPs inherent in efficient arguments? %A Guy Rothblum %A Salil Vadhan %X
Version History: Special Issue on CCC '09.
Starting with Kilian (STOC ‘92), several works have shown how to use probabilistically checkable proofs (PCPs) and cryptographic primitives such as collision-resistant hashing to construct very efficient argument systems (a.k.a. computationally sound proofs), for example with polylogarithmic communication complexity. Ishai et al. (CCC ‘07) raised the question of whether PCPs are inherent in efficient arguments, and if so, to what extent. We give evidence that they are, by showing how to convert any argument system whose soundness is reducible to the security of some cryptographic primitive into a PCP system whose efficiency is related to that of the argument system and the reduction (under certain complexity assumptions).
%B Computational Complexity %V 19 %P 265-304 %G eng %U https://link.springer.com/article/10.1007/s00037-010-0291-3 %N 2 %0 Conference Paper %B Daniele Micciancio, editor, Proceedings of the 7th IACR Theory of Cryptography Conference (TCC ‘10), Lecture Notes on Computer Science %D 2010 %T Composition of zero-knowledge proofs with efficient provers %A Eleanor Birrell %A Salil Vadhan %XWe revisit the composability of different forms of zero- knowledge proofs when the honest prover strategy is restricted to be polynomial time (given an appropriate auxiliary input). Our results are:
Version History: Full version posted as Cryptology ePrint Archive Report 210/241.
Following Gennaro, Gentry, and Parno (Cryptology ePrint Archive 2009/547), we use fully homomorphic encryption to design improved schemes for delegating computation. In such schemes, a delegator outsources the computation of a function \({F}\) on many, dynamically chosen inputs \(x_i\) to a worker in such a way that it is infeasible for the worker to make the delegator accept a result other than \({F}(x_i)\). The “online stage” of the Gennaro et al. scheme is very efficient: the parties exchange two messages, the delegator runs in time poly\((\log{T})\), and the worker runs in time poly\((T)\), where \(T\) is the time complexity of \(F\). However, the “offline stage” (which depends on the function \(F\) but not the inputs to be delegated) is inefficient: the delegator runs in time poly\((T)\) and generates a public key of length poly\((T)\) that needs to be accessed by the worker during the online stage.
Our first construction eliminates the large public key from the Gennaro et al. scheme. The delegator still invests poly\((T)\) time in the offline stage, but does not need to communicate or publish anything. Our second construction reduces the work of the delegator in the offline stage to poly\((\log{T})\) at the price of a 4-message (offline) interaction with a poly\((T)\)-time worker (which need not be the same as the workers used in the online stage). Finally, we describe a “pipelined” implementation of the second construction that avoids the need to re-run the offline construction after errors are detected (assuming errors are not too frequent).
%B T. Rabin, editor, Advances in Cryptology—CRYPTO ‘10, Lecture Notes in Computer Science %I Springer-Verlag %V 6223 %P 483-501 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-14623-7_26 %0 Conference Paper %B Proceedings of the 51st Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘10) %D 2010 %T The limits of two-party differential privacy %A McGregor, Andrew %A Ilya Mironov %A Toniann Pitassi %A Omer Reingold %A Kunal Talwar %A Salil Vadhan %XVersion History and Errata: Subsequent version published in ECCC 2011. Proposition 8 and Part (b) of Theorem 13 in the FOCS version are incorrect, and are removed from the ECCC version.
We study differential privacy in a distributed setting where two parties would like to perform analysis of their joint data while preserving privacy for both datasets. Our results imply almost tight lower bounds on the accuracy of such data analyses, both for specific natural functions (such as Hamming distance) and in general. Our bounds expose a sharp contrast between the two-party setting and the simpler client-server setting (where privacy guarantees are one-sided). In addition, those bounds demonstrate a dramatic gap between the accuracy that can be obtained by differentially private data analysis versus the accuracy obtainable when privacy is relaxed to a computational variant of differential privacy. The first proof technique we develop demonstrates a connection between differential privacy and deterministic extraction from Santha-Vazirani sources. A second connection we expose indicates that the ability to approximate a function by a low-error differentially private protocol is strongly related to the ability to approximate it by a low communication protocol. (The connection goes in both directions).
%B Proceedings of the 51st Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘10) %I IEEE %P 81-90 %G eng %U https://ieeexplore.ieee.org/document/5670946 %0 Journal Article %J Journal of the ACM %D 2009 %T Unbalanced expanders and randomness extractors from Parvaresh–Vardy codes %A Venkatesan Guruswami %A Christopher Umans %A Salil Vadhan %XVersion History: Preliminary versions of this article appeared as Technical Report TR06-134 in Electronic Colloquium on Computational Complexity, 2006, and in Proceedings of the 22nd Annual IEEE Conference on Computional Complexity (CCC '07), pp. 96–108. Preliminary version recipient of Best Paper Award at CCC '07.
We give an improved explicit construction of highly unbalanced bipartite expander graphs with expansion arbitrarily close to the degree (which is polylogarithmic in the number of vertices). Both the degree and the number of right-hand vertices are polynomially close to optimal, whereas the previous constructions of Ta-Shma et al. [2007] required at least one of these to be quasipolynomial in the optimal. Our expanders have a short and self-contained description and analysis, based on the ideas underlying the recent list-decodable error-correcting codes of Parvaresh and Vardy [2005].
Our expanders can be interpreted as near-optimal “randomness condensers,” that reduce the task of extracting randomness from sources of arbitrary min-entropy rate to extracting randomness from sources of min-entropy rate arbitrarily close to 1, which is a much easier task. Using this connection, we obtain a new, self-contained construction of randomness extractors that is optimal up to constant factors, while being much simpler than the previous construction of Lu et al. [2003] and improving upon it when the error parameter is small (e.g., 1/poly(n)).
%B Journal of the ACM %V 56 %P 1–34 %G eng %U http://delivery.acm.org.ezp-prod1.hul.harvard.edu/10.1145/1540000/1538904/a20-guruswami.pdf?ip=206.253.207.235&id=1538904&acc=ACTIVE%20SERVICE&key=AA86BE8B6928DDC7%2EC82FBC3DCC335AD2%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35&__acm__=1571939126_5ae5ffacdd25b4a %N 4 %0 Journal Article %J SIAM Journal on Computing %D 2009 %T Statistically hiding commitments and statistical zero-knowledge arguments from any one-way function %A Iftach Haitner %A Nguyen, Minh %A Shien Jin Ong %A Omer Reingold %A Salil Vadhan %X Version History: Special Issue on STOC ‘07. Merge of papers from FOCS ‘06 and STOC ‘07. Received SIAM Outstanding Paper Prize 2011.
We give a construction of statistically hiding commitment schemes (those in which the hiding property holds against even computationally unbounded adversaries) under the minimal complexity assumption that one-way functions exist. Consequently, one-way functions suffice to give statistical zero-knowledge arguments for any NP statement (whereby even a computationally unbounded adversarial verifier learns nothing other than the fact that the assertion being proven is true, and no polynomial-time adversarial prover can convince the verifier of a false statement). These results resolve an open question posed by Naor et al. [J. Cryptology, 11 (1998), pp. 87–108].
Version History: Preliminary version posted as Cryptology ePrint Archive Report 2008/097, March 2008.
We provide a simple protocol for secret reconstruction in any threshold secret sharing scheme, and prove that it is fair when executed with many rational parties together with a small minority of honest parties. That is, all parties will learn the secret with high probability when the honest parties follow the protocol and the rational parties act in their own self-interest (as captured by a set-Nash analogue of trembling hand perfect equilibrium). The protocol only requires a standard (synchronous) broadcast channel, tolerates both early stopping and incorrectly computed messages, and only requires 2 rounds of communication.
Previous protocols for this problem in the cryptographic or economic models have either required an honest majority, used strong communication channels that enable simultaneous exchange of information, or settled for approximate notions of security/equilibria. They all also required a nonconstant number of rounds of communication.
%B O. Reingold, editor, Proceedings of the Fourth Theory of Cryptography Conference (TCC ‘09), Lecture Notes in Computer Science %I Springer-Verlag %V 5444 %P 36-53 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-00457-5_3 %0 Conference Paper %B O. Reingold, editor, Proceedings of the Fourth Theory of Cryptography Conference (TCC ‘09), Lecture Notes in Computer Science %D 2009 %T Proofs of retrievability via hardness amplification %A Yevgeniy Dodis %A Salil Vadhan %A Daniel Wichs %XVersion History: Originally presented at Theory of Cryptography Conference (TCC) 2009. Full version published in Cryptology ePrint Archive (attached as ePrint2009).
Proofs of Retrievability (PoR), introduced by Juels and Kaliski [JK07], allow the client to store a file F on an untrusted server, and later run an efficient audit protocol in which the server proves that it (still) possesses the client’s data. Constructions of PoR schemes attempt to minimize the client and server storage, the communication complexity of an audit, and even the number of file-blocks accessed by the server during the audit. In this work, we identify several different variants of the problem (such as bounded-use vs. unbounded-use, knowledge-soundness vs. information-soundness), and giving nearly optimal PoR schemes for each of these variants. Our constructions either improve (and generalize) the prior PoR constructions, or give the first known PoR schemes with the required properties. In particular, we
The main insight of our work comes from a simple connection between PoR schemes and the notion of hardness amplification, extensively studied in complexity theory. In particular, our im- provements come from first abstracting a purely information-theoretic notion of PoR codes, and then building nearly optimal PoR codes using state-of-the-art tools from coding and complexity theory.
%B O. Reingold, editor, Proceedings of the Fourth Theory of Cryptography Conference (TCC ‘09), Lecture Notes in Computer Science %I Springer-Verlag %V 5444 %P 109-127 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-00457-5_8 %0 Conference Paper %B Proceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC ‘09) %D 2009 %T On the complexity of differentially private data release: Efficient algorithms and hardness results %A Cynthia Dwork %A Moni Naor %A Omer Reingold %A Guy Rothblum %A Salil Vadhan %X We consider private data analysis in the setting in which a trusted and trustworthy curator, having obtained a large data set containing private information, releases to the public a "sanitization" of the data set that simultaneously protects the privacy of the individual contributors of data and offers utility to the data analyst. The sanitization may be in the form of an arbitrary data structure, accompanied by a computational procedure for determining approximate answers to queries on the original data set, or it may be a "synthetic data set" consisting of data items drawn from the same universe as items in the original data set; queries are carried out as if the synthetic data set were the actual input. In either case the process is non-interactive; once the sanitization has been released the original data and the curator play no further role. For the task of sanitizing with a synthetic dataset output, we map the boundary between computational feasibility and infeasibility with respect to a variety of utility measures. For the (potentially easier) task of sanitizing with unrestricted output format, we show a tight qualitative and quantitative connection between hardness of sanitizing and the existence of traitor tracing schemes. %B Proceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC ‘09) %I ACM %P 381-390 %G eng %U https://dl.acm.org/citation.cfm?id=1536467 %0 Conference Paper %B Proceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC ‘09) %D 2009 %T Inaccessible entropy %A Iftach Haitner %A Omer Reingold %A Salil Vadhan %A Hoeteck Wee %XWe put forth a new computational notion of entropy, which measures the (in)feasibility of sampling high entropy strings that are consistent with a given protocol. Specifically, we say that the \(i\)’th round of a protocol \((\mathsf{A,B})\) has accessible entropy at most \(k\), if no polynomial-time strategy \(\mathsf{A}^*\) can generate messages for \(\mathsf{A}\) such that the entropy of its message in the \(i\)’th round has entropy greater than \(k\) when conditioned both on prior messages of the protocol and on prior coin tosses of \(\mathsf{A}^*\). We say that the protocol has inaccessible entropy if the total accessible entropy (summed over the rounds) is noticeably smaller than the real entropy of \(\mathsf{A}\)’s messages, conditioned only on prior messages (but not the coin tosses of \(\mathsf{A}\)). As applications of this notion, we
Give a much simpler and more efficient construction of statistically hiding commitment schemes from arbitrary one- way functions.
Prove that constant-round statistically hiding commitments are necessary for constructing constant-round zero-knowledge proof systems for NP that remain secure under parallel composition (assuming the existence of one-way functions).
Version History: Preliminary version posted as ECCC TR08-103.
We show that every bounded function \({g} \) : \(\{0,1\}^n \to [0,1]\) admits an efficiently computable "simulator" function \({h} \) : \(\{0,1\}^n \to [0,1]\) such that every fixed polynomial size circuit has approximately the same correlation with \({g}\) as with \({h}\). If g describes (up to scaling) a high min-entropy distribution \(D\), then \({h}\) can be used to efficiently sample a distribution \(D'\) of the same min-entropy that is indistinguishable from \(D\) by circuits of fixed polynomial size. We state and prove our result in a more abstract setting, in which we allow arbitrary finite domains instead of \(\{0,1\}^n\), and arbitrary families of distinguishers, instead of fixed polynomial size circuits. Our result implies (a) the weak Szemeredi regularity Lemma of Frieze and Kannan (b) a constructive version of the dense model theorem of Green, Tao and Ziegler with better quantitative parameters (polynomial rather than exponential in the distinguishing probability), and (c) the Impagliazzo hardcore set Lemma. It appears to be the general result underlying the known connections between "regularity" results in graph theory, "decomposition" results in additive combinatorics, and the hardcore Lemma in complexity theory. We present two proofs of our result, one in the spirit of Nisan's proof of the hardcore Lemma via duality of linear programming, and one similar to Impagliazzo's "boosting" proof. A third proof by iterative partitioning, which gives the complexity of the sampler to be exponential in the distinguishing probability, is also implicit in the Green-Tao-Ziegler proofs of the dense model theorem.
%B Proceedings of the 24th Annual IEEE Conference on Computational Complexity (CCC ‘09) %I IEEE %P 126-136 %G eng %U https://ieeexplore.ieee.org/document/5231258 %0 Conference Paper %B S. Halevi, editor, Advances in Cryptology—CRYPTO ‘09, Lecture Notes in Computer Science %D 2009 %T Computational differential privacy %A Ilya Mironov %A Omkant Pandey %A Omer Reingold %A Salil Vadhan %XThe definition of differential privacy has recently emerged as a leading standard of privacy guarantees for algorithms on statistical databases. We offer several relaxations of the definition which require privacy guarantees to hold only against efficient—i.e., computationally-bounded—adversaries. We establish various relationships among these notions, and in doing so, we observe their close connection with the theory of pseudodense sets by Reingold et al.[1]. We extend the dense model theorem of Reingold et al. to demonstrate equivalence between two definitions (indistinguishability-and simulatability-based) of computational differential privacy.
Our computational analogues of differential privacy seem to allow for more accurate constructions than the standard information-theoretic analogues. In particular, in the context of private approximation of the distance between two vectors, we present a differentially-private protocol for computing the approximation, and contrast it with a substantially more accurate protocol that is only computationally differentially private.
%B S. Halevi, editor, Advances in Cryptology—CRYPTO ‘09, Lecture Notes in Computer Science %I Springer-Verlag %V 5677 %P 126-142 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-03356-8_8 %0 Conference Paper %B Proceedings of the 13th International Workshop on Randomization and Computation (RANDOM ‘09), Lecture Notes in Computer Science %D 2009 %T Pseudorandom bit generators that fool modular sums %A Shachar Lovett %A Omer Reingold %A Luca Trevisan %A Salil Vadhan %XWe consider the following problem: for given \(n, M,\) produce a sequence \(X_1, X_2, . . . , X_n\) of bits that fools every linear test modulo \(M\). We present two constructions of generators for such sequences. For every constant prime power \(M\), the first construction has seed length \(O_M(\log(n/\epsilon))\), which is optimal up to the hidden constant. (A similar construction was independently discovered by Meka and Zuckerman [MZ]). The second construction works for every \(M, n,\) and has seed length \(O(\log n + \log(M/\epsilon) \log( M \log(1/\epsilon)))\).
The problem we study is a generalization of the problem of constructing small bias distributions [NN], which are solutions to the \(M=2\) case. We note that even for the case \(M=3\) the best previously known con- structions were generators fooling general bounded-space computations, and required \(O(\log^2 n)\) seed length.
For our first construction, we show how to employ recently constructed generators for sequences of elements of \(\mathbb{Z}_M\) that fool small-degree polynomials modulo \(M\). The most interesting technical component of our second construction is a variant of the derandomized graph squaring operation of [RV]. Our generalization handles a product of two distinct graphs with distinct bounds on their expansion. This is then used to produce pseudorandom walks where each step is taken on a different regular directed graph (rather than pseudorandom walks on a single regular directed graph as in [RTV, RV]).
%B Proceedings of the 13th International Workshop on Randomization and Computation (RANDOM ‘09), Lecture Notes in Computer Science %I Springer-Verlag %V 5687 %P 615-630 %G eng %U https://link.springer.com/chapter/10.1007/978-3-642-03685-9_46 %0 Journal Article %J SIAM Journal on Computing: Special Issue on STOC '05 %D 2008 %T The round complexity of two-party random selection %A Saurabh Sanghvi %A Salil Vadhan %XVersion History. Preliminary versions of this work appeared in the first author's undergraduate thesis and in the conference paper (STOC '05).
We study the round complexity of two-party protocols for generating a random \(n\)-bit string such that the output is guaranteed to have bounded “bias,” even if one of the two parties deviates from the protocol (possibly using unlimited computational resources). Specifically, we require that the output’s statistical difference from the uniform distribution on \(\{0, 1\}^n\) is bounded by a constant less than 1. We present a protocol for the above problem that has \(2\log^* n + O(1)\) rounds, improving a previous 2\(n\)-round protocol of Goldreich, Goldwasser, and Linial (FOCS ’91). Like the GGL Protocol, our protocol actually provides a stronger guarantee, ensuring that the output lands in any set \(T ⊆ \{0, 1\}^n\) of density \(μ\) with probability at most \(O( \sqrt{μ + δ})\), where \(δ\) may be an arbitrarily small constant. We then prove a nearly matching lower bound, showing that any protocol guaranteeing bounded statistical difference requires at least \(\log^* n−\log^* \log^* n−O(1)\) rounds. We also prove several results for the case when the output’s bias is measured by the maximum multiplicative factor by which a party can increase the probability of a set \(T ⊆ \{0, 1\}^n\)
%B SIAM Journal on Computing: Special Issue on STOC '05 %V 38 %P 523-550 %G eng %U https://epubs.siam.org/doi/abs/10.1137/050641715 %N 2 %0 Conference Proceedings %B In Proceedings of the Third Theory of Cryptography Conference (TCC '08), 4948:501-534 %D 2008 %T Interactive and noninteractive zero knowledge are equivalent in the help model %A André Chailloux %A Dragos Florin Ciocan %A Iordanis Kerenidis %A Salil Vadhan %XVersion History:
We show that interactive and noninteractive zero-knowledge are equivalent in the ‘help model’ of Ben-Or and Gutfreund (J. Cryptology, 2003). In this model, the shared reference string is generated by a probabilistic polynomial-time dealer who is given access to the statement to be proven. Our results do not rely on any unproven complexity assumptions and hold for statistical zero knowledge, for computational zero knowledge restricted to AM, and for quantum zero knowledge when the help is a pure quantum state.
%B In Proceedings of the Third Theory of Cryptography Conference (TCC '08), 4948:501-534 %I Springer-Verlag, Lecture Notes in Computer Science %V 4948 %P 501–534 %G eng %U https://link.springer.com/chapter/10.1007/978-3-540-78524-8_28 %0 Conference Paper %B R. Canetti, editor, Proceedings of the Third Theory of Cryptography Conference (TCC ‘08) %D 2008 %T An equivalence between zero knowledge and commitments. %A Shien Jin Ong %A Salil Vadhan %XWe show that a language in NP has a zero-knowledge protocol if and only if the language has an “instance-dependent” commitment scheme. An instance-dependent commitment schemes for a given language is a commitment scheme that can depend on an instance of the language, and where the hiding and binding properties are required to hold only on the yes and no instances of the language, respectively.
The novel direction is the only if direction. Thus, we confirm the widely held belief that commitments are not only sufficient for zero knowledge protocols, but necessary as well. Previous results of this type either held only for restricted types of protocols or languages, or used nonstandard relaxations of (instance-dependent) commitment schemes.
%B R. Canetti, editor, Proceedings of the Third Theory of Cryptography Conference (TCC ‘08) %I Springer Verlag, Lecture Notes in Computer Science %V 4948 %P 482-500 %G eng %U https://link.springer.com/chapter/10.1007/978-3-540-78524-8_27 %0 Conference Paper %B Proceedings of the 12th International Workshop on Randomization and Computation (RANDOM ‘08), Lecture Notes in Computer Science %D 2008 %T Limitations on hardness vs. randomness under uniform reductions %A Dan Gutfreund %A Salil Vadhan %XWe consider (uniform) reductions from computing a function \({f}\) to the task of distinguishing the output of some pseudorandom generator \({G}\) from uniform. Impagliazzo and Wigderson [10] and Trevisan and Vadhan [24] exhibited such reductions for every function \({f}\) in PSPACE. Moreover, their reductions are “black box,” showing how to use any distinguisher \({T}\), given as oracle, in order to compute \({f}\) (regardless of the complexity of \({T}\) ). The reductions are also adaptive, but with the restriction that queries of the same length do not occur in different levels of adaptivity. Impagliazzo and Wigderson [10] also exhibited such reductions for every function \({f}\) in EXP, but those reductions are not black-box, because they only work when the oracle \({T}\) is computable by small circuits.
Our main results are that:
– Nonadaptive black-box reductions as above can only exist for functions \({f}\) in BPPNP (and thus are unlikely to exist for all of PSPACE).
– Adaptive black-box reductions, with the same restriction on the adaptivity as above, can only exist for functions \({f}\) in PSPACE (and thus are unlikely to exist for all of EXP).
Beyond shedding light on proof techniques in the area of hardness vs. randomness, our results (together with [10,24]) can be viewed in a more general context as identifying techniques that overcome limitations of black-box reductions, which may be useful elsewhere in complexity theory (and the foundations of cryptography).
%B Proceedings of the 12th International Workshop on Randomization and Computation (RANDOM ‘08), Lecture Notes in Computer Science %I Springer-Verlag %V 5171 %P 469-482 %G eng %U https://link.springer.com/chapter/10.1007%2F978-3-540-85363-3_37 %0 Conference Paper %B Proceedings of the 12th International Workshop on Randomization and Computation (RANDOM ‘08), Lecture Notes in Computer Science %D 2008 %T The complexity of distinguishing Markov random fields %A Andrej Bogdanov %A Elchanan Mossel %A Salil Vadhan %XMarkov random fields are often used to model high dimensional distributions in a number of applied areas. A number of recent papers have studied the problem of reconstructing a dependency graph of bounded degree from independent samples from the Markov random field. These results require observing samples of the distribution at all nodes of the graph. It was heuristically recognized that the problem of reconstructing the model where there are hidden variables (some of the variables are not observed) is much harder.
Here we prove that the problem of reconstructing bounded-degree models with hidden nodes is hard. Specifically, we show that unless NP = RP,
The second problem remains hard even if the samples are generated efficiently, albeit under a stronger assumption.
%B Proceedings of the 12th International Workshop on Randomization and Computation (RANDOM ‘08), Lecture Notes in Computer Science %I Springer-Verlag %V 5171 %P 331-342 %G eng %U https://link.springer.com/chapter/10.1007/978-3-540-85363-3_27 %0 Conference Paper %B Proceedings of the 49th Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘08) %D 2008 %T Dense subsets of pseudorandom sets %A Omer Reingold %A Luca Trevisan %A Madhur Tulsiani %A Salil Vadhan %X A theorem of Green, Tao, and Ziegler can be stated (roughly) as follows: if R is a pseudorandom set, and D is a dense subset of R, then D may be modeled by a set M that is dense in the entire domain such that D and M are indistinguishable. (The precise statement refers to "measures" or distributions rather than sets.) The proof of this theorem is very general, and it applies to notions of pseudo-randomness and indistinguishability defined in terms of any family of distinguishers with some mild closure properties. The proof proceeds via iterative partitioning and an energy increment argument, in the spirit of the proof of the weak Szemeredi regularity lemma. The "reduction" involved in the proof has exponential complexity in the distinguishing probability. We present a new proof inspired by Nisan's proof of Impagliazzo's hardcore set theorem. The reduction in our proof has polynomial complexity in the distinguishing probability and provides a new characterization of the notion of "pseudoentropy" of a distribution. A proof similar to ours has also been independently discovered by Gowers [2]. We also follow the connection between the two theorems and obtain a new proof of Impagliazzo's hardcore set theorem via iterative partitioning and energy increment. While our reduction has exponential complexity in some parameters, it has the advantage that the hardcore set is efficiently recognizable. %B Proceedings of the 49th Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘08) %I IEEE %P 76-85 %G eng %U https://ieeexplore.ieee.org/document/4690942 %0 Conference Paper %B Advances in Cryptology–EUROCRYPT '07 %D 2007 %T Zero knowledge and soundness are symmetric %A Shien Jin Ong %A Salil Vadhan %XVersion History: Recipient of Best Paper Award. Preliminary version posted on ECCC as TR06-139, November 2006.
We give a complexity-theoretic characterization of the class of problems in NP having zero-knowledge argument systems. This characterization is symmetric in its treatment of the zero knowledge and the soundness conditions, and thus we deduce that the class of problems in NP \(\bigcap\) coNP having zero-knowledge arguments is closed under complement. Furthermore, we show that a problem in NP has a statistical zero-knowledge argument \(\)system if and only if its complement has a computational zero-knowledge proof system. What is novel about these results is that they are unconditional, i.e., do not rely on unproven complexity assumptions such as the existence of one-way functions.
Our characterization of zero-knowledge arguments also enables us to prove a variety of other unconditional results about the class of problems in NP having zero-knowledge arguments, such as equivalences between honest-verifier and malicious-verifier zero knowledge, private coins and public coins, inefficient provers and efficient provers, and non-black-box simulation and black-box simulation. Previously, such results were only known unconditionally for zero-knowledge proof systems, or under the assumption that one-way functions exist for zero-knowledge argument systems.
%B Advances in Cryptology–EUROCRYPT '07 %I Springer Verlag, Lecture Notes in Computer Science, M. Naor, ed. %C Barcelona, Spain %V 4515 %P 187-209 %G eng %U https://link.springer.com/chapter/10.1007/978-3-540-72540-4_11 %0 Journal Article %J Information Processing Letters %D 2007 %T The hardness of the expected decision depth problem %A Dana Ron %A Amir Rosenfeld %A Salil Vadhan %XGiven a function \(f\) over \(n\) binary variables, and an ordering of the \(n\) variables, we consider the Expected Decision Depth problem. Namely, what is the expected number of bits that need to be observed until the value of the function is determined, when bits of the input are observed according to the given order. Our main finding is that this problem is (essentially) #P-complete. Moreover, the hardness holds even when the function f is represented as a decision tree.
%B Information Processing Letters %V 101 %P 112-118 %G eng %U https://www.sciencedirect.com/science/article/pii/S0020019006002730 %N 3 %0 Conference Paper %B A. Menezes, editor, Advances in Cryptology (CRYPTO '07) %D 2007 %T Amplifying collision-resistance: A complexity-theoretic treatment %A Ran Canetti %A Ron Rivest %A Madhu Sudan %A Luca Trevisan %A Salil Vadhan %A Hoeteck Wee %XWe initiate a complexity-theoretic treatment of hardness amplification for collision-resistant hash functions, namely the transformation of weakly collision-resistant hash functions into strongly collision-resistant ones in the standard model of computation. We measure the level of collision resistance by the maximum probability, over the choice of the key, for which an efficient adversary can find a collision. The goal is to obtain constructions with short output, short keys, small loss in adversarial complexity tolerated, and a good trade-off between compression ratio and computational complexity. We provide an analysis of several simple constructions, and show that many of the parameters achieved by our constructions are almost optimal in some sense.
%B A. Menezes, editor, Advances in Cryptology (CRYPTO '07) %I Lecture Notes in Computer Science, Springer-Verlag %V 4622 %P 264-283 %G eng %U https://link.springer.com/chapter/10.1007/978-3-540-74143-5_15 %0 Journal Article %J SIAM Journal on Computing: Special Issue on Randomness and Complexity %D 2006 %T Robust PCPs of proximity, shorter PCPs, and applications to coding %A Eli Ben-Sasson %A Oded Goldreich %A Prahladh Harsha %A Madhu Sudan %A Salil Vadhan %XVersion History. Extended abstract in STOC '04.
We continue the study of the trade-off between the length of probabilistically checkable proofs (PCPs) and their query complexity, establishing the following main results (which refer to proofs of satisfiability of circuits of size \(n\)):
In both cases, false assertions are rejected with constant probability (which may be set to be arbitrarily close to 1). The multiplicative overhead on the length of the proof, introduced by transforming a proof into a probabilistically checkable one, is just quasi polylogarithmic in the first case (of query complexity \(o(\log \log n)\)), and is \(2^{(\log n)^ε} \), for any \(ε > 0\), in the second case (of constant query complexity). Our techniques include the introduction of a new variant of PCPs that we call “robust PCPs of proximity.” These new PCPs facilitate proof composition, which is a central ingredient in the construction of PCP systems. (A related notion and its composition properties were discovered independently by Dinur and Reingold.) Our main technical contribution is a construction of a “length-efficient” robust PCP of proximity. While the new construction uses many of the standard techniques used in PCP constructions, it does differ from previous constructions in fundamental ways, and in particular does not use the “parallelization” step of Arora et al. [J. ACM, 45 (1998), pp. 501–555]. The alternative approach may be of independent interest. We also obtain analogous quantitative results for locally testable codes. In addition, we introduce a relaxed notion of locally decodable codes and present such codes mapping \(k\) information bits to codewords of length \(k^{1+ε}\) for any \(ε > 0\).
%B SIAM Journal on Computing: Special Issue on Randomness and Complexity %V 36 %P 889-974 %G eng %U https://epubs.siam.org/doi/abs/10.1137/S0097539705446810 %N 4 %0 Journal Article %J SIAM Journal on Computing: Special Issue on STOC '04 %D 2006 %T Using nondeterminism to amplify hardness %A Alex Healy %A Salil Vadhan %A Emanuele Viola %XWe revisit the problem of hardness amplification in \(\mathcal{NP}\) as recently studied by O’Donnell [J. Comput. System Sci., 69 (2004), pp. 68–94]. We prove that if \(\mathcal{NP}\) has a balanced function \(f\) such that any circuit of size \(s(n)\) fails to compute \(f\) on a \(1/\mathrm{poly}(n)\) fraction of inputs, then \(\mathcal{NP}\) has a function \(f'\) such that any circuit of size \(s'(n) = s(\sqrt{n})^{\Omega(1)}\) fails to compute \(f\) on a \(1/2 − 1/s' (n)\) fraction of inputs. In particular,
Our results improve those of of O’Donnell, which amplify to\(1/2 - 1/ \sqrt{n}\). O’Donnell also proved that no construction of a certain general form could amplify beyond \(1/2 - 1/n\). We bypass this barrier by using both derandomization and nondeterminism in the construction of \(f'\). We also prove impossibility results demonstrating that both our use of nondeterminism and the hypothesis that \(f\) is balanced are necessary for “black-box” hardness amplification procedures (such as ours).
%B SIAM Journal on Computing: Special Issue on STOC '04 %V 35 %P 903-931 %G eng %U https://epubs.siam.org/doi/abs/10.1137/S0097539705447281 %N 4 %0 Journal Article %J SIAM Journal on Computing: Special Issue on Randomness and Complexity %D 2006 %T An unconditional study of computational zero knowledge %A Salil Vadhan %XVersion History: Extended abstract in FOCS '04.
We prove a number of general theorems about \(\mathbf{ZK}\), the class of problems possessing (computational) zero-knowledge proofs. Our results are unconditional, in contrast to most previous works on \(\mathbf{ZK}\), which rely on the assumption that one-way functions exist. We establish several new characterizations of \(\mathbf{ZK}\) and use these characterizations to prove results such as the following:
The above equalities refer to the resulting class of problems (and do not necessarily preserve other efficiency measures such as round complexity). Our approach is to combine the conditional techniques previously used in the study of \(\mathbf{ZK}\) with the unconditional techniques developed in the study of \(\mathbf{SZK}\), the class of problems possessing statistical zero-knowledge proofs. To enable this combination, we prove that every problem in \(\mathbf{ZK}\) can be decomposed into a problem in \(\mathbf{SZK}\) together with a set of instances from which a one-way function can be constructed.
%B SIAM Journal on Computing: Special Issue on Randomness and Complexity %V 36 %P 1160-1214 %G eng %U https://epubs.siam.org/doi/10.1137/S0097539705447207 %N 4 %0 Conference Paper %B Proceedings of the 38th Annual ACM Symposium on Theory of Computing (STOC ‘06) %D 2006 %T Pseudorandom walks in regular digraphs and the RL vs. L problem %A Omer Reingold %A Luca Trevisan %A Salil Vadhan %XVersion History: Preliminary version as ECCC TR05-22, February 2005 (https://eccc.weizmann.ac.il/report/2005/022/; attached as ECCC2005.pdf).
We revisit the general \(\mathbf{RL}\) vs. \(\mathbf{L}\) question, obtaining the following results.
Version History. Full version available at https://eccc.weizmann.ac.il//eccc-reports/2005/TR05-093/ (Attached as ECCC2005).
We provide unconditional constructions of concurrent statistical zero-knowledge proofs for a variety of non-trivial problems (not known to have probabilistic polynomial-time algorithms). The problems include Graph Isomorphism, Graph Nonisomorphism, Quadratic Residuosity, Quadratic Nonresiduosity, a restricted version of Statistical Difference, and approximate versions of the (\(\mathsf{coNP}\) forms of the) Shortest Vector Problem and Closest Vector Problem in lattices. For some of the problems, such as Graph Isomorphism and Quadratic Residuosity, the proof systems have provers that can be implemented in polynomial time (given an \(\mathsf{NP}\) witness) and have \(\tilde{O}(\log n)\) rounds, which is known to be essentially optimal for black-box simulation. To the best of our knowledge, these are the first constructions of concurrent zero-knowledge proofs in the plain, asynchronous model (i.e., without setup or timing assumptions) that do not require complexity assumptions (such as the existence of one-way functions).
%B S. Halevi and T. Rabin, eds., Proceedings of the Third Theory of Cryptography Conference (TCC '06) %I Springer Verlag, Lecture Notes in Computer Science %C New York, NY, USA %V 3876 %P 1-20 %G eng %U https://link.springer.com/chapter/10.1007/11681878_1 %0 Conference Paper %B Proceedings of the 38th Annual ACM Symposium on Theory of Computing (STOC ‘06) %D 2006 %T Zero knowledge with efficient provers %A Nguyen, Minh %A Salil Vadhan %X We prove that every problem in NP that has a zero-knowledge proof also has a zero-knowledge proof where the prover can be implemented in probabilistic polynomial time given an NP witness. Moreover, if the original proof system is statistical zero knowledge, so is the resulting efficient-prover proof system. An equivalence of zero knowledge and efficient-prover zero knowledge was previously known only under the assumption that one-way functions exist (whereas our result is unconditional), and no such equivalence was known for statistical zero knowledge. Our results allow us to translate the many general results and characterizations known for zero knowledge with inefficient provers to zero knowledge with efficient provers. %B Proceedings of the 38th Annual ACM Symposium on Theory of Computing (STOC ‘06) %I ACM %P 287-295 %G eng %U https://dl.acm.org/doi/abs/10.1145/1132516.1132559 %0 Conference Paper %B Advances in Cryptology—CRYPTO ‘06, C. Dwork, ed. %D 2006 %T Random selection with an adversarial majority %A Ronen Gradwohl %A Salil Vadhan %A David Zuckerman %XVersion History: Full version published in ECCC TR 06-026, February 2006. Updated full version published June 2006.
We consider the problem of random selection, where \(p\) players follow a protocol to jointly select a random element of a universe of size \(n\). However, some of the players may be adversarial and collude to force the output to lie in a small subset of the universe. We describe essentially the first protocols that solve this problem in the presence of a dishonest majority in the full-information model (where the adversary is computationally unbounded and all communication is via non-simultaneous broadcast). Our protocols are nearly optimal in several parameters, including the round complexity (as a function of \(n\)), the randomness complexity, the communication complexity, and the tradeoffs between the fraction of honest players, the probability that the output lies in a small subset of the universe, and the density of this subset.
%B Advances in Cryptology—CRYPTO ‘06, C. Dwork, ed. %I Springer Verlag, Lecture Notes in Computer Science %V 4117 %P 409–426 %G eng %U https://link.springer.com/chapter/10.1007/11818175_25 %0 Conference Paper %B Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘06) %D 2006 %T Statistical zero-knowledge arguments for NP from any one-way function %A Minh-Huyen Nguyen %A Shien Jin Ong %A Salil Vadhan %XVersion History: Merged with STOC '07 paper of Haitner and Reingold. Also available as a journal version. Full version invited to SIAM J. Computing Special Issue on FOCS ‘06
We show that every language in NP has a statistical zero-knowledge argument system under the (minimal) complexity assumption that one-way functions exist. In such protocols, even a computationally unbounded verifier cannot learn anything other than the fact that the assertion being proven is true, whereas a polynomial-time prover cannot convince the verifier to accept a false assertion except with negligible probability. This resolves an open question posed by Naor et al. (1998). Departing from previous works on this problem, we do not construct standard statistically hiding commitments from any one-way function. Instead, we construct a relaxed variant of commitment schemes called "1-out-of-2-binding commitments," recently introduced by Nguyen et al. (2006)
%B Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS ‘06) %I IEEE %P 3-13 %G eng %U https://ieeexplore.ieee.org/document/4031338 %0 Journal Article %J Computational Complexity: Special Issue on CCC'04 %D 2005 %T Compression of samplable sources %A Luca Trevisan %A Salil Vadhan %A David Zuckerman %XWe study the compression of polynomially samplable sources. In particular, we give efficient prefix-free compression and decompression algorithms for three classes of such sources (whose support is a subset of \(\{0, 1\}^n\)).
We introduce a “derandomized” analogue of graph squaring. This operation increases the connectivity of the graph (as measured by the second eigenvalue) almost as well as squaring the graph does, yet only increases the degree of the graph by a constant factor, instead of squaring the degree.
One application of this product is an alternative proof of Reingold’s recent breakthrough result that S-T Connectivity in Undirected Graphs can be solved in deterministic logspace.
%B Proceedings of the 8th International Workshop on Randomization and Computation (RANDOM '05) %I Springer Verlag, Lecture Notes in Computer Science %C Berkeley, CA %V 3624 %P 436-447 %G eng %U https://link.springer.com/chapter/10.1007/11538462_37 %0 Journal Article %J Journal of the ACM %D 2003 %T A complete problem for statistical zero knowledge. %A Amit Sahai %A Salil Vadhan %X We present the first complete problem for SZK, the class of (promise) problems possessing statistical zero-knowledge proofs (against an honest verifier). The problem, called STATISTICAL DIFFERENCE, is to decide whether two efficiently samplable distributions are either statistically close or far apart. This gives a new characterization of SZK that makes no reference to interaction or zero knowledge.
We propose the use of complete problems to unify and extend the study of statistical zero knowledge. To this end, we examine several consequences of our Completeness Theorem and its proof, such as:
We model the environment by an unknown directed graph G, and consider the problem of a robot exploring and mapping G. The edges emanating from each vertex are numbered from `1' to `d', but we do not assume that the vertices of G are labeled. Since the robot has no way of distinguishing between vertices, it has no hope of succeeding unless it is given some means of distinguishing between vertices. For this reason we provide the robot with a "pebble" --- a device that it can place on a vertex and use to identify the vertex later.
In this paper we show:
We give several efficient transformations for manipulating the statistical difference (variation distance) between a pair of probability distributions. The effects achieved include increasing the statistical difference, decreasing the statistical difference, "polarizing" the statistical relationship, and "reversing" the statistical relationship. We also show that a boolean formula whose atoms are statements about statistical difference can be transformed into a single statement about statistical difference. All of these transformations can be performed in polynomial time, in the sense that, given circuits which sample from the input distributions, it only takes polynomial time to compute circuits which sample from the output distributions.
By our prior work (see FOCS 97), such transformations for manipulating statistical difference are closely connected to results about SZK, the class of languages possessing statistical zero-knowledge proofs. In particular, some of the transformations given in this paper are equivalent to the closure of SZK under complement and under certain types of Turing reductions. This connection is also discussed briefly in this paper.
%B Randomization Methods in Algorithm Design (DIMACS Workshop, December 1997), volume 43 of DIMACS Series in Discrete Mathematics and Theoretical Computer Science %V 43 %P 251-270 %G eng %0 Journal Article %J Internet RFC %D 1999 %T Key management for multicast: Issues and architectures. %A D. Wallner %A E. Harder %A R. Agee %XThis report contains a discussion of the difficult problem of key management for multicast communication sessions. It focuses on two main areas of concern with respect to key management, which are, initializing the multicast group with a common net key and rekeying the multicast group. A rekey may be necessary upon the compromise of a user or for other reasons (e.g., periodic rekey). In particular, this report identifies a technique which allows for secure compromise recovery, while also being robust against collusion of excluded users. This is one important feature of multicast key management which has not been addressed in detail by most other multicast key management proposals [1,2,4]. The benefits of this proposed technique are that it minimizes the number of transmissions required to rekey the multicast group and it imposes minimal storage requirements on the multicast group.
%B Internet RFC %V 2627 %G eng %N June 1999 %0 Journal Article %J Proceedings of the 30th Annual ACM Symposium on Theory of Computing (STOC ‘98) %D 1998 %T Honest-verifier statistical zero-knowledge equals general statistical zero-knowledge. %A Oded Goldreich %A Amit Sahai %A Salil Vadhan %X We show how to transform any interactive proof system which is statistical zero-knowledge with respect to the honest-verifier, into a proof system which is statistical zero-knowledge with respect to any verifier. This is done by limiting the behavior of potentially cheating verifiers, without using computational assumptions or even referring to the complexity of such verifier strategies. (Previous transformations have either relied on computational assumptions or were applicable only to constant-round public-coin proof systems.)Our transformation also applies to public-coin (aka Arthur-Merlin) computational zero-knowledge proofs: We transform any Arthur-Merlin proof system which is computational zero-knowledge with respect to the honest-verifier, into an Arthur-Merlin proof system which is computational zero-knowledge with respect to any probabilistic polynomial-time verifier.
A crucial ingredient in our analysis is a new lemma regarding 2-universal hashing functions.
%B Proceedings of the 30th Annual ACM Symposium on Theory of Computing (STOC ‘98) %P 399-408 %G eng